들어가며
MariaDB에서 Buffer Pool은 자주 액세스하는 데이터를 빠르게 처리할 수 있는 메모리 영역으로 액세스되는 데이터를 저장하고 관리한다. 데이터를 읽거나 쓸 때 Buffer 관리자는 해당 데이터를 Buffer Cache 영역에 로딩하여 빠른 데이터 액세스를 가능하게 하며, Buffer Pool이 가득 차면 오래되었거나 자주 사용되지 않는 Data Page가 Disk로 이동하게 된다.
이번 인사이트 레포트에서는 InnoDB Buffer Pool의 이해와 최적화 방안이라는 주제로 1부와 2부에 걸쳐 설명을 진행 할 예정이며, 1부에서는 MariaDB의 주요 구조와 Buffer Pool 동작 방식에 대하여 알아보고자 한다. 10.5 이상부터 버전에 따른 InnoDB Buffer Pool 구조에 많은 변화가 있었다. 기본적인 Buffer Pool에 대한 이해를 돕기 위해 이전 버전을 기준으로 개념적 이해를 돕고, 이후 변경된 내용에 대해 작성하였으니 참고하길 바란다.
MariaDB의 구조
Buffer Pool의 내용을 이해하기 위하여 몇가지 주요한 MariaDB의 아키텍처 및 역할에 대해 소개 하겠다.
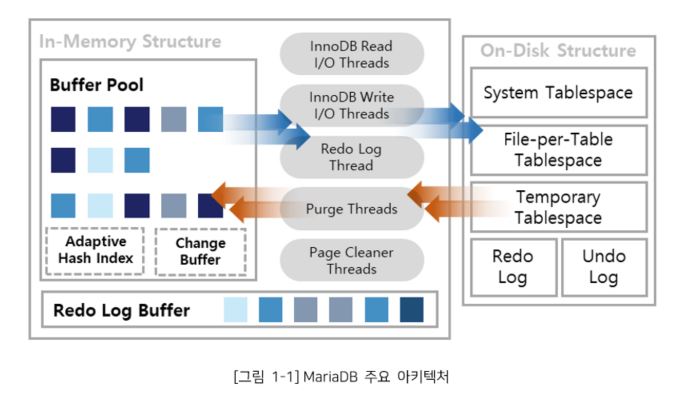
InnoDB Memory의 주요 구성 요소는 다음과 같다.

InnoDB Background Thread의 주요 구성요소는 다음과 같다.

MariaDB에서 지원하는 다양한 Storage Engine 중 InnoDB Storage Engine은 트랜잭션 지원과 데이터 무결성을 지원하는 대표적인 Storage Engine 이다.
InnoDB Storage Engine의 구성요소는 다음과 같다.

Buffer Pool은 어떻게 동작하나?
1. Buffer Pool의 역할 및 기능
InnoDB Storage Engine은 트랜잭션에서 자주 사용되는 데이터와 인덱스 데이터를 캐싱하기 위해 InnoDB Buffer Pool을 사용한다.
트랜잭션 처리 시 데이터의 읽기 및 쓰기 작업은 먼저 Buffer Pool에서 이루어지며, 이것은 자주 액세스되는 데이터를 메모리에 유지하여 디스크 I/O를 줄이고 이를 통해 데이터 액세스 속도가 향상시켜 트랜잭션의 일관성과 안정적인 성능 유지에 도움이 된다. 그러나 Buffer Pool이 가득 차면 오래된 Data Page들은LRU 알고리즘에 의해 Aging-Out 된다.
● 데이터 로딩
데이터베이스가 시작될 때나 데이터베이스 서버가 실행 중일 때 Buffer Pool은 초기화 되며, 메모리 공간을 할당 받고 디스크에 저장된 Data Page를 순차적으로 메모리 버퍼에 로딩 하게 된다. 이로써 자주 액세스되는 데이터가 메모리에 준비 된다. 이는 Buffer Pool이 실제로 유용해 지기까지 일정기간이 필요하다는 것을 의미하는데, 이 기간을 워밍업이라고 한다. 이 워밍업 기간을 줄여주기 위해 10.0부터 DB가 종료되기 전에 Buffer Pool을 덤프를 수행하고 다시 시작할 때 복원이 가능하도록 기능이 추가되었으며, 이 기능을 사용하면 워밍업이 필요하지 않게 된다. 워밍업 기능은 10.2부터 기본적으로 활성화 되었고, “innodb_buffer_pool_dump_at_shutdown” 과 “innodb_buffer_pool_ load_at_startup” 변수를 이용하여 활성화 및 비활성화 할 수 있다.
● 데이터 덤프
서버가 실행되는 동안 언제든지 InnoDB Buffer Pool을 덤프 할 수 있으며, 마지막 Buffer Pool 덤프를 언제든지 복원하는 것도 가능하다. 덤프를 실행하기 위해서는 “innodb_buffer_pool_dump_now” 와 “innodb_buffer_pool_load_now” 변수로 ON / OFF 설정할 수 있고, “innodb_buffer_pool_load_abort” 값을 ON으로 설정하면 Startup하거나 어떤 순간에도 Buffer Pool 복원을 중단 할 수 있다. Buffer Pool 덤프 내용이 포함되는 파일은 “innodb_buffer_pool_filename” 변수로 지정 가능하다.
2. Buffer Pool의 구조
1) Buffer Pool 영역 구성
InnoDB는 Buffer Pool에서 모든 캐싱을 수행하며, “innodb_buffer_pool_size”에 의해 크기가 제어된다. 기본적으로 Open Table에 대한 Data 및 Index 블록 (“innodb_page_size”에 정의 된 사이즈 기준)을 포함하고, 약간의 유지관리에 필요한 오버헤드가 추가 된다.
InnoDB Buffer Pool은 10.4 버전까지는 buffer Pool의 크기에 따라 한 개 이상의 인스턴스로 구성되고, 하나의 인스턴스는 chunk 및 인스턴스를 관리하기 위한 여러가지 영역으로 구성되어 있다. 반면에 10.5.1 버전부터는 InnoDB Buffer Pool 인스턴스는 하나로 구성된다.
MariaDB 10.4까지는 “innodb_buffer_pool_size” 설정값이 1G 이상일 경우 “innodb_buffer_pool_instances” 변수의 기본값이 8로 설정 되었지만, 10.5.1부터는 Instance 분리에 대한 성능적인 이점이 없다고 판단됨에 따라 해당 변수가 Deprecated 되었으며, 10.6부터는 Removed 되었다.
Page hash에는 bucket에 대한 array 주소 값을 가지고 있고 이 bucket에는 Hash Table에 대한 정보를 가지며, Chunk는 데이터를 저장하기 위한 block들을 가지고 있다.
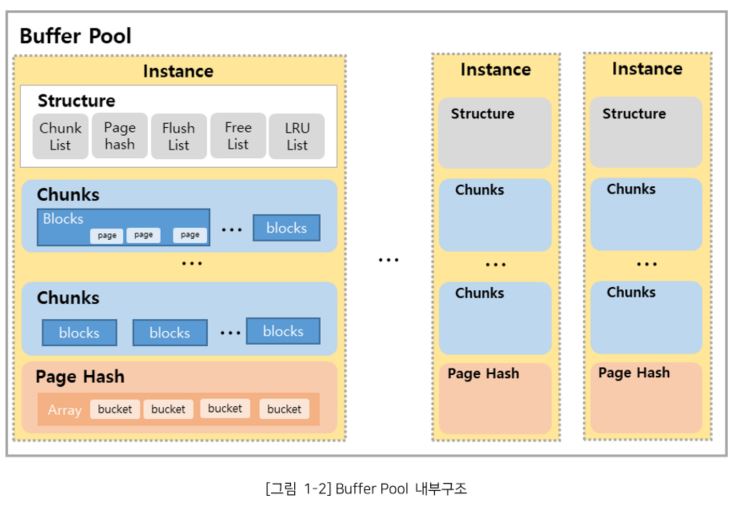
2) Buffer Pool 인스턴스 관리 리스트
Buffer Pool 인스턴스 내에는 인스턴스를 관리하기 위한 3가지 리스트(free, LRU, Flush_List)가 있다.

“Free”는 사용 가능한 Data Page를 관리하는 Free List로, 새로운 Data Page의 할당이 필요하면 이 리스트에서 획득 할 수 있다.
“LRU”는 Free에서 Page를 할당 받은 LRU 목록이고, Clean 상태이거나 Dirty Page가 모두 존재한다. 만약 Page에 변경이 생성되면 해당 Page의 State에 “Dirty Page”라는 것을 표시한다. LRU는 Young List 와 Old List 두가지 파트로 나뉘는데, Old List는 새롭게 읽은 Page를 저장하고 Young List는 HOT Page를 저장한다. 만일 Old List에서 이동 조건이 충족되면 Young List로 옮겨 간다. Buffer Pool의 총 Buffer 개수는 Free + LRU 개수가 된다.
“Flush list”는 모든 Dirty Page를 포함하는데 이는 리스트의 모든 Page가 수정되었으나 디스크에 쓰여지지 않은 상태를 의미한다. 그래서, Dirty Page는 Flush list와 LRU에 이중으로 존재하게 되며, Write I/O Threads가 Dirty Page를 메모리에서 디스크로 내려쓰면 LRU의 Dirty Page의 state가 변경되고 Flush list에서는 삭제 된다.
3) Dirty Page
“Dirty Page” 관리는 InnoDB Storage Engine 내부에서 발생하는 중요한 메커니즘 중 하나로, Page의 데이터가 메모리에서만 변경되고 아직 디스크에는 기록되지 못한 Page를 말한다. 이를 관리하고 디스크에 적절히 기록하는 것은 데이터의 일관성과 내구성을 보장하기 위해 매우 중요하다.
Dirty Page 관리에 관한 절차는 다음과 같다.
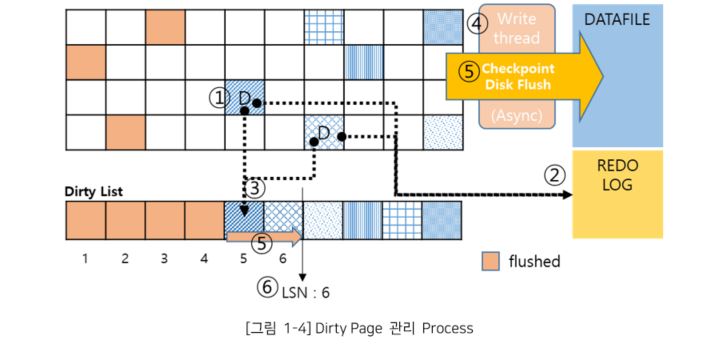
① 데이터 변경: 사용자 또는 어플리케이션에 의해 데이터가 변경되면 해당 Data Page는 Dirty Page가 된다. 이 변경은 메모리 내부에서 수행되며, 해당 Page는 Disk와 일치하지 않은 상태이다.
② Redo Log 생성: 변경된 데이터는 Redo Log에 기록된다. 이 Log는 변경 작업을 기록하는 로그로써, 시스템 장애 등의 상황에서 데이터 복구를 지원한다.
③ Data Page 갱신: 변경된 Data Page는 메모리의 “Dirty List”에 추가 된다. 이 리스트를 디스크에 아직 기록되지 않은 변경된 Page들을 추적하는 역할을 한다.
④ Checkpoint: 주기적으로 Dirty Page들 중에서 일부를 Disk에 기록하는 작업이 수행된다. 이를 “Checkpoint”라고 하는데, 디스크의 데이터와 메모리의 데이터를 일치 시키는 역할을 한다.
⑤ Flush 작업: Checkpoint에 의해 결정된 Dirty Page들은 Disk에 기록된다. 이를 “Flush”라고 하며, 데이터의 내구성을 확보하는 과정이다.
⑥ LSN(Log Sequence Number): Flush된 Page의 LSN이 갱신된다. 이는 데이터가 어느 부분까지 Disk에 기록 되었는지를 추적하는 중요한 정보이다.
1) LRU (Least Recently Used) 알고리즘
Buffer Pool은 변형된 LRU 알고리즘을 사용하여 목록으로 관리한다. Buffer Pool에 새 Page를 추가하는데 공간이 필요한 경우, 가장 최근에 사용된 Page가 제거되고 새 Page가 목록 중간에 추가 된다. 이 중간점 삽입 전략은 목록을 두 개의 Sublist, 즉 최근에 사용된 정보의 New Sublist(이하, New List)와 이전 정보의 Old Sublist(이하, Old List)로 작동 한다. 기본적으로 목록의 37%(3/8)가 Old List로 예약 되어 있다.
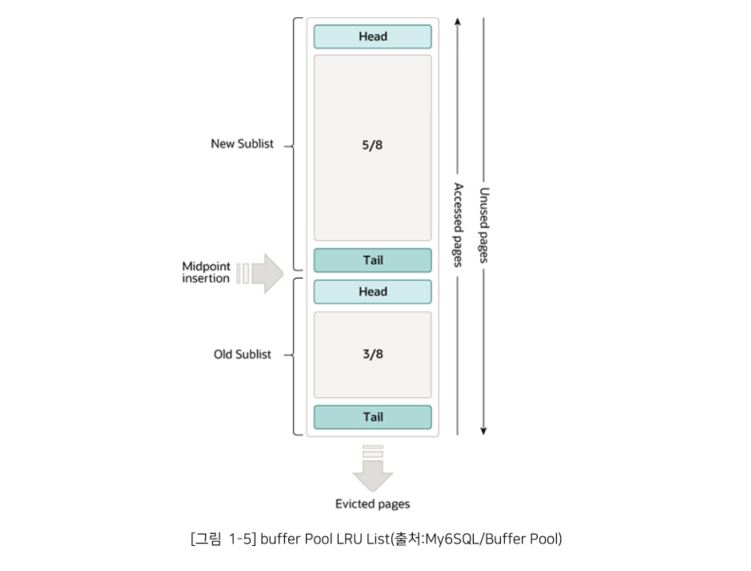
Buffer Pool의 크기는 제한적이기 때문에 모든 Data Page를 한 번에 메모리에 유지할 수 없다. 따라서 가장 최근에 사용되지 않은 Data Page는 메모리에서 삭제될 수 있어야 한다.
LRU 알고리즘의 동작 방식은 다음과 같다.
① Buffer Pool의 3/8 은 Old List 목록에 할당 된다.
② LRU의 Midpoint(이하, 중간점)은 New List의 Tail과 Old List의 Head가 만나는 경계에 있다.
③ InnoDB Page를 Buffer Pool로 읽을 때 처음에는 중간점(Old List의 Head 부분)에 삽입한다.
④ Old List에 있는 Page에 액세스하면 해당 Page는 New List로 이동하게 된다.
⑤ 액세스 되지않은 Buffer Pool의 Page는 Old List의 Tail로 이동되면서 Evicted 된다.
Buffer Pool은 자주 사용되는 블록을 Buffer에 보관하려고 시도하며, 목록에 나타나지 않는 새로운 정보에 액세스 하면 Old List의 맨 위에 배치되고, Old List에서 가장 오래된 항목을 제거되어 다른 모든 정보는 목록에서 한 위치 뒤로 이동하게 된다. Old List에 나타나는 정보에 접근하면 해당 정보는 New List의 맨 위로 이동되고 위의 모든 항목은 한 위치 뒤로 이동된다.
여기서 읽어오는 데이터에는 실제 사용자 쿼리에 의해 요청된 데이터도 있을 수 있지만, Read-Ahead1) 에 의해 자동적으로 읽어오는 데이터도 포함되며, 이 데이터는 young list로 취급하지 않는다.
1) Read-Ahead: 요청된 Page가 곧 필요할 경우를 대비하여 Page 그룹(전체 범위)을 Buffer Pool에 비동기식으로 메모리에 미리 올려놓는(Prefetch) 방식
마치며
1부 인사이트 리포트에서는 MariaDB에 대한 주요 구조와 Buffer Pool의 동작 방식에 대해 살펴보았다. 2부 인사이트 리포트에서는 MariaDB의 Buffer Pool을 모니터링 하고 최적화 하기 위하여 확인해야 할 시스템 변수 및 상태 변수를 알아보고 어떤 부분을 확인을 해야 할지 알아 보도록 하겠다.
# References
- https://mariadb.com/kb/en/innodb-buffer-pool/
- https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
- https://mariadb.com/kb/en/setting-innodb-buffer-pool-size-dynamically/
- https://mariadb.com/kb/en/innodb-page-flushing/
- https://mariadb.com/kb/en/innodb-system-variables/
- https://mariadb.com/kb/en/mariadb-memory-allocation/
- https://mariadb.com/kb/en/understanding-mariadb-architecture/
- https://mariadb.com/kb/en/setting-innodb-buffer-pool-size-dynamically/
- https://mariadb.com/docs/server/architecture/components/enterprise-server/innodb/background-thread-pool/
- https://mariadb.com/docs/server/storage-engines/innodb/operations/configure-io-threads/
- https://www.percona.com/blog/tuning-mysql-innodb-flushing-for-a-write-intensive-workload/
- Exem Deep Internals Series II – Oracle, PostgreSQL, MySQL Core Architecture II (㈜엑셈)

임주연 프로
소프트웨어사업부 OSS사업팀
에스코어 OSS기술그룹에서 오픈소스DB와 관련된 전문가로 기술지원 업무를 하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.