들어가며
Redis에서 클러스터는 Redis 노드의 수평 확장이 가능하도록 자동화된 샤딩 기능으로 사용자가 대용량 트래픽을 처리할 수 있도록 한다.
여러 Redis 노드를 클러스터로 그룹화하는 Redis의 클러스터링의 핵심 개념 중 하나는 해시 슬롯을 사용한다는 점이다. 클러스터의 각 Redis 서버는 특정 범위의 해시 슬롯을 담당하며, 해시 슬롯에 매핑되는 모든 key는 해당 Redis 서버에 저장된다. 이러한 프로세스는 key가 서버 간에 골고루 분산되어 고가용성 및 성능, 안정성이 향상시킬 수 있다.
Redis에서 클러스터링의 또 다른 중요한 측면은 Split-brain의 개념이다.
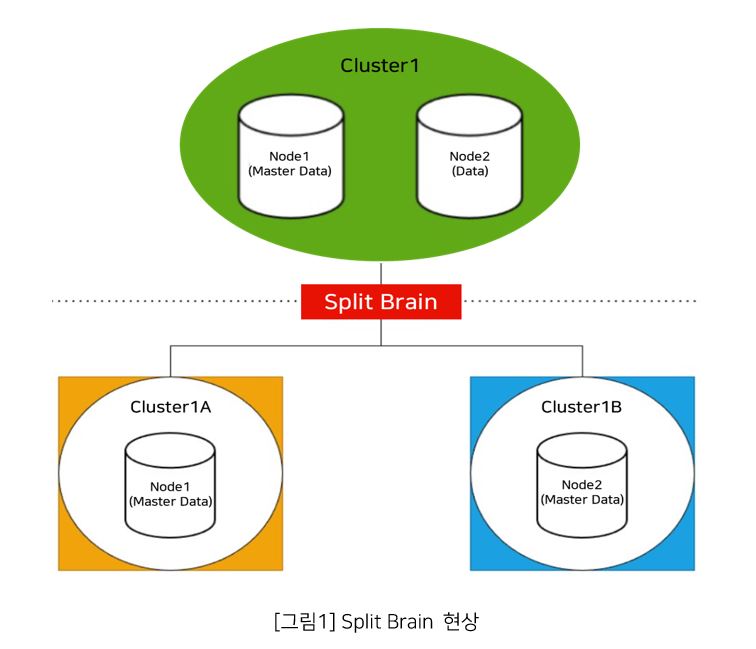
Split-brain은 네트워크 토폴로지를 갖는 프로덕션 환경에서 네트워크 파티셔닝 장애로 인해 클러스터가 서브 클러스터로 분할되어 모든 노드들이 자신이 Primary라고 인식하게 되는 상황을 의미한다. Split-brain이 발생하면, 클러스터가 분할됨으로써 이중 가동 현상이 발생하고, 동시에 스토리지 자원에 접근하기 때문에 데이터 동기화 및 복제에 비정상적인 트랜잭션을 발생시킨다.
이는 Redis에서 클러스터가 분할될 때 발생할 수 있으며, Split-brain에 대한 네트워크 이슈로 인해 일부 Redis 서버는 연결이 끊기거나 더 이상 통신할 수 없는 상태가 될 수 있다.
이 상황에서 Redis는 클러스터를 계속 사용할 수 있지만 데이터의 손실 및 정합성이 깨지는 것을 방지하기 위한 메커니즘을 갖추고 있다.
본 아티클에서는 Redis 클러스터 측면에서 네트워크 이슈에 대해 안정적인 아키텍처 설계 및 운영 관리 방법에 대해 살펴보겠다.
1. Redis 클러스터의 고가용성(High Availability)
Redis 클러스터는 각 Primary와 Replica 노드들을 클러스터링하여 하나의 시스템처럼 동작한다. 여기서 Redis 클러스터의 고가용성은 가동 중인 Primary 샤드가 죽거나 통신이 되지 않을 때에 실패할 때를 감지하고, 외부의 수동 개입 없이 Replica가 Primary로 승격함으로써 작업을 계속할 수 있도록 지속적인 시스템 운영을 보장한다.
다음 예제와 같이 Redis 클러스터의 고가용성(HA) 아키텍처를 알아보고, 구성은 모든 Primary 샤드당 하나의 Replica가 있으며, 여기서 Primary 3대와 Replica 3대로 구성된 아키텍처이다.
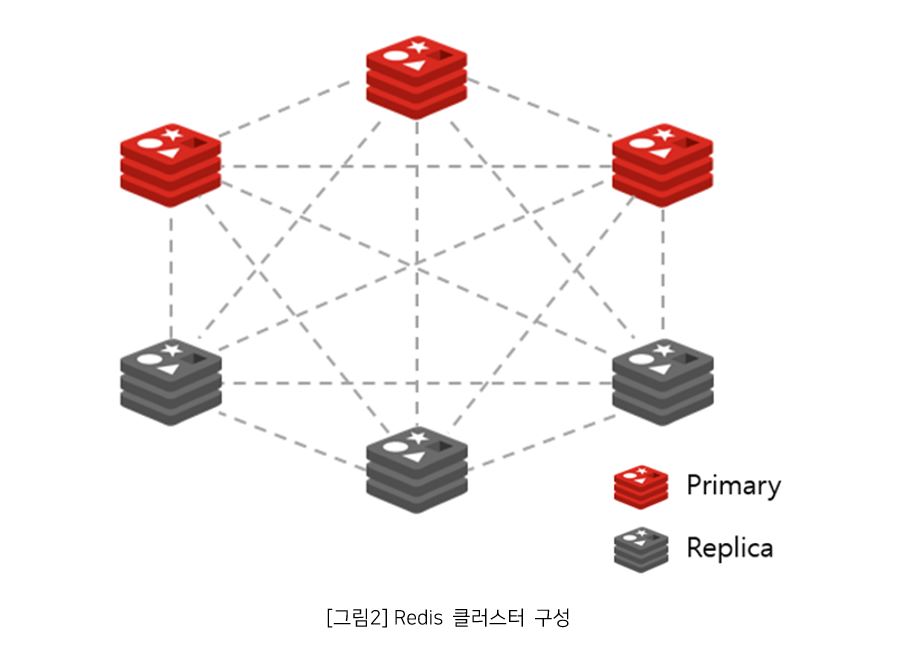
Redis 클러스터 구성

Redis Server (Cluster mode) 실행

Redis 클러스터의 Primary에 Replica 추가

Redis 클러스터에 Primary와 Replica 연결 확인

2. Redis 클러스터에서 Split-brain 상황
Redis 클러스터는 3개의 기본(Primary) 샤드와 3개의 복제(Replica)로 이루어진 총 6개 노드로 구성되었다.
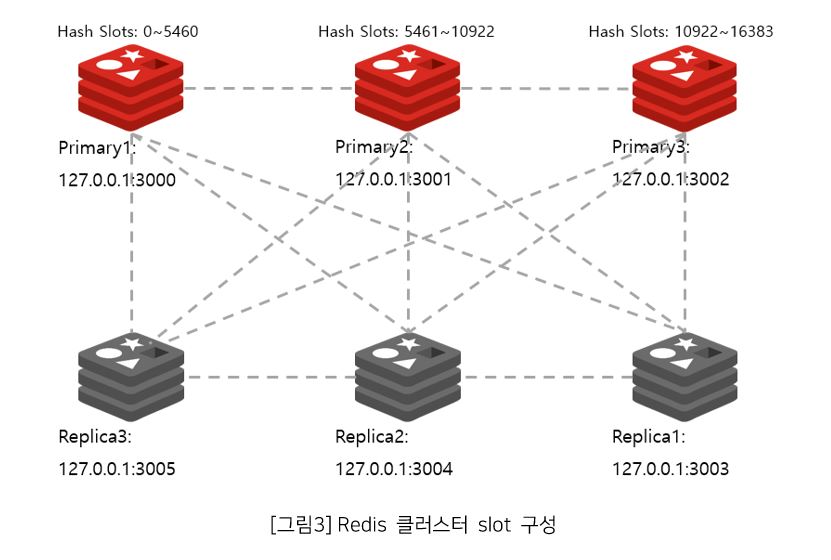
2.1 네트워크 파티셔닝 발생
구성된 클러스터에서는 네트워크 파티셔닝이 발생했다고 가정한다. 즉, 왼쪽 그룹이 오른쪽 그룹의 샤드와 연결이 끊겨 통신할 수 없는 상황이다.

이제, 두 클러스터 그룹의 모든 샤드는 자신이 오프라인이라고 생각하고 두 그룹은 기본 샤드의 failover를 트리거하여 왼쪽에는 모든 기본 샤드가 있고, 오른쪽에도 마찬가지로 모든 기본 샤드가 있다.
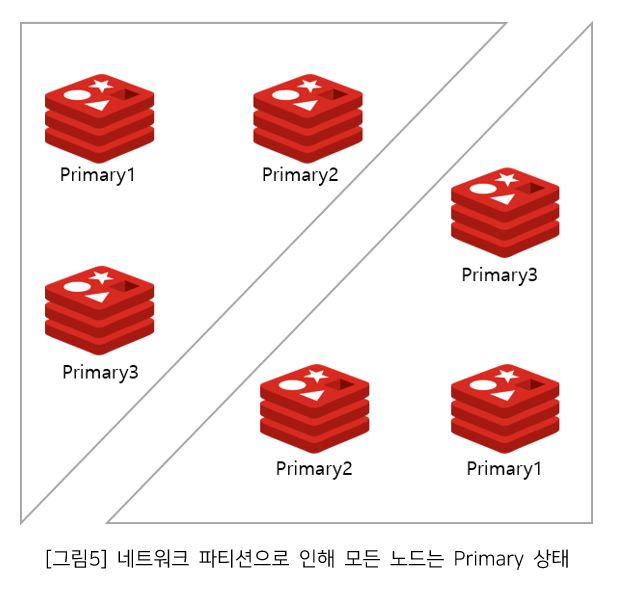
2.2 두 그룹으로 분할된 서브 클러스터에서 데이터를 수신
양쪽 클러스터 모두 자신이 Primary를 가지고 있다고 생각하고, 클라이언트의 데이터를 계속 수신 대기 한다. 만약 클라이언트A가 Key_A의 value를 “abc”로 설정하지만 클라이언트B는 동일한 Key_A의 값을 “def”로 설정함으로써, 문제가 될 수 있다.
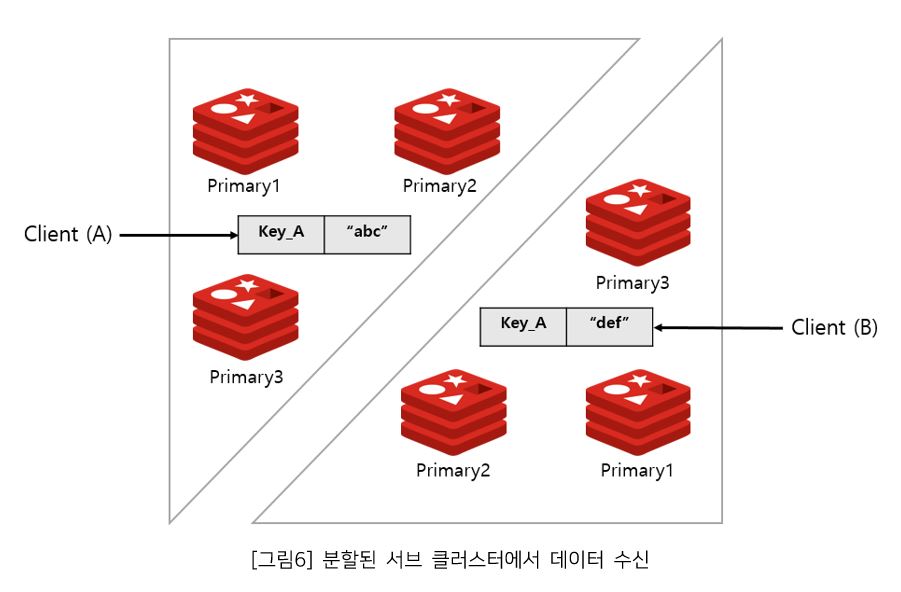
2.3 Split-brain 발생으로 인해 데이터 정합성 이슈
네트워크 파티션이 제거되고 샤드가 다시 결합한다면 이전 두 클러스터 그룹에서 데이터 수신으로 인해 다른 데이터를 보유한 상태로 Primary라고 주장하는 두 개의 샤드가 있어서 어떤 데이터가 유효한지 알 수 없기 때문에 충돌이 발생한다.
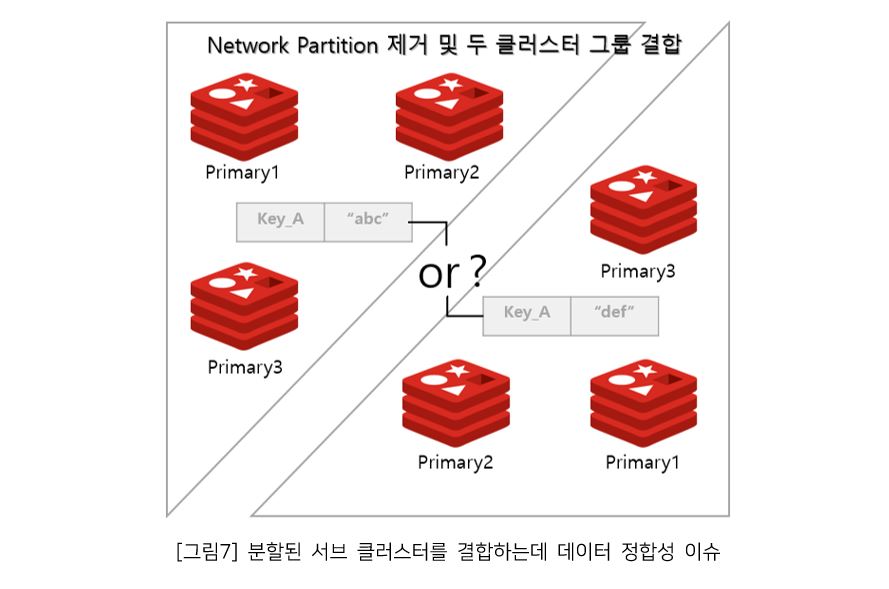
이것을 Split-brain 상황이라고 하며, 분산 시스템에서 발생할 수 있는 하나의 이슈이다.
3. Split-brain 상황에서 Redis 클러스터에 대한 해결책
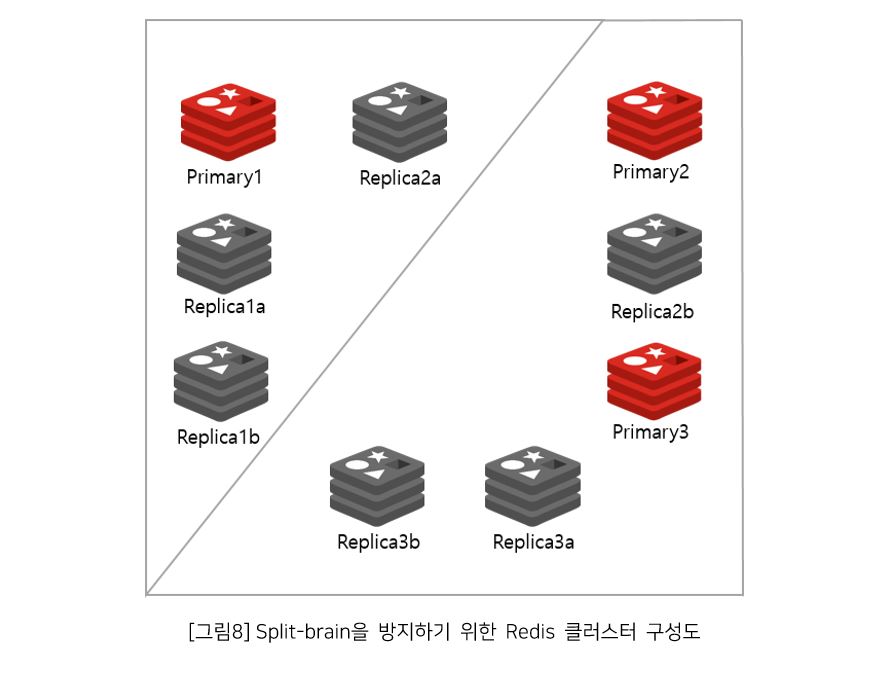
- Redis 클러스터에서 Split-brain 상황을 방지하려면 클러스터에 항상 홀수 개의 샤드를 유지하는 것이다.
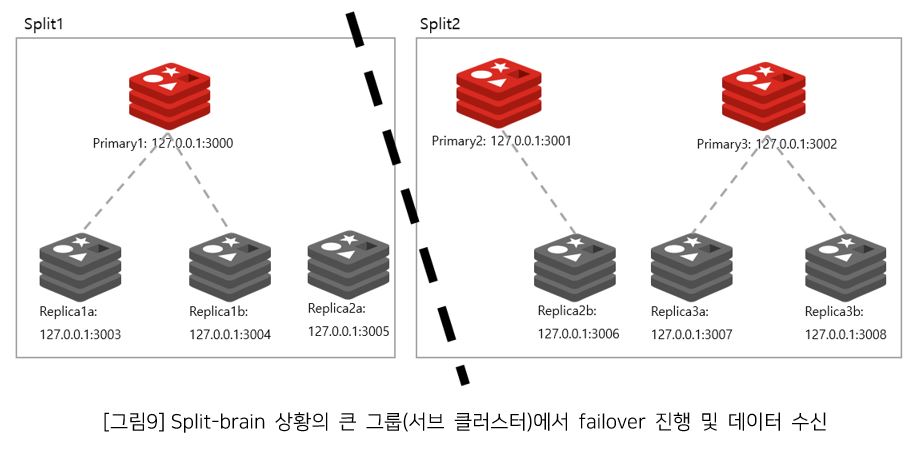
- Network Partition이 발생할 때, 왼쪽 및 오른쪽 그룹의 샤드 개수를 카운팅하고, 큰 그룹(다수의 샤드)과 작은 그룹(소수의 샤드)을 분류 및 확인한다.
- 클러스터는 그룹 중 작은 그룹(소수의 샤드)에 속하면 failover를 하지 않고 클라이언트의 write 요청을 수락하지 않는다.
- 반면, 큰 그룹(다수의 샤드)은 failover를 진행하여 클라이언트의 write 요청을 수락한다.
마치며
Redis 클러스터에서 네트워크 파티션 장애로 인한 Split-brain 상황과 해결책에 대해 알아보았다.
Split-brain은 클러스터링 또는 다중 노드 및 스토리지 구성의 각 종 솔루션(GlusterFS 파일 분산복제 설정, HA 용도 등)에서 장애로 발생시키는 요인이며, 프로덕션 환경에서 점검해야 할 중요한 아키텍처적 점검 대상에 해당한다. 이에 대해 IT 개발자 및 운영관리자는 본 아티클의 내용을 참고하여 고가용성 클러스터를 안정적으로 운영하는데 도움이 되기를 바란다.
# References
- https://redis.io/docs/reference/cluster-spec/
- https://redis.com/blog/learn-clustering-from-redis-experts/
- https://developer.redis.com/operate/redis-at-scale/scalability/lustering-in-redis/
- https://en.wikipedia.org/wiki/Split-brain_(computing)
- https://bigdataboutique.com/blog/avoiding-the-elasticsearch-split-brain-problem-and-how-to-recover-f6451c

김남욱 프로
소프트웨어사업부 OSS사업팀
클라우드 및 오픈소스 SW 관련 연구 개발 프로젝트를 수행하였으며, 현재 OSS 기술서비스 및 아키텍처를 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.