들어가며
벡터 검색은 데이터 간의 유사성을 기반으로 하는 고급 검색 기술로, 기존의 키워드 기반 검색을 한층 더 발전시킨 것이다. 키워드 검색은 단순히 일치하는 단어나 문구를 찾는 방식이지만, 벡터 검색은 데이터 포인트를 고차원 벡터 공간에 매핑하여 데이터 간의 유사성을 측정한다. 이를 통해 더 복잡하고 정교한 검색이 가능해지며, 특히 자연어 처리(NLP), 이미지 및 비디오 검색, 추천 시스템 등에서 뛰어난 성능을 발휘한다.
이러한 벡터 검색의 필요성은 디지털 정보의 양과 복잡성이 증가함에 따라 더욱 커지고 있다. 기존의 검색 방식으로는 비정형 데이터(예: 이미지, 오디오, 자연어 텍스트 등)를 효율적으로 처리하기 어렵기 때문에, 이를 활용한 벡터 검색이 중요해졌다. 이 기술은 다양한 산업 분야에서 적용 가능하며, 데이터 간의 미묘한 유사성을 정확하게 파악할 수 있어 사용자의 요구를 보다 잘 충족시킬 수 있다.
특히, RAG (Retrieval-Augmented Generation) 모델은 벡터 검색과 생성형 AI 기술을 결합하여 더 나은 검색 결과를 제공하는 데 사용되고 있다. RAG는 검색 쿼리에 대해 벡터화된 문서 집합에서 유사한 데이터를 검색한 후, 이 데이터를 바탕으로 새로운 텍스트를 생성하는 기술이다. 이를 통해 사용자는 보다 정교하고 맥락에 맞는 검색 결과를 얻을 수 있다. 예를 들어, 고객 서비스 챗봇은 RAG를 사용해 사용자의 질문에 맞춤형 답변을 제공할 수 있다.
Elastic도 이러한 기술 발전에 맞춰 벡터 검색 기능을 크게 강화하고 있다. 전통적으로 강력한 텍스트 기반 검색 기능을 제공해온 Elasticsearch는 이제 벡터 검색을 통해 이미지나 자연어와 같은 복잡한 데이터 유형에서도 뛰어난 성능을 제공한다. 특히, Elastic은 RAG와 같은 모델을 효과적으로 지원할 수 있는 기능들을 통해, 다양한 산업에서 사용자의 요구를 만족시킬 수 있는 포괄적인 솔루션을 제공한다.
Elastic VectorDB의 강점: 확장성과 효율성을 갖춘 고성능 검색 솔루션
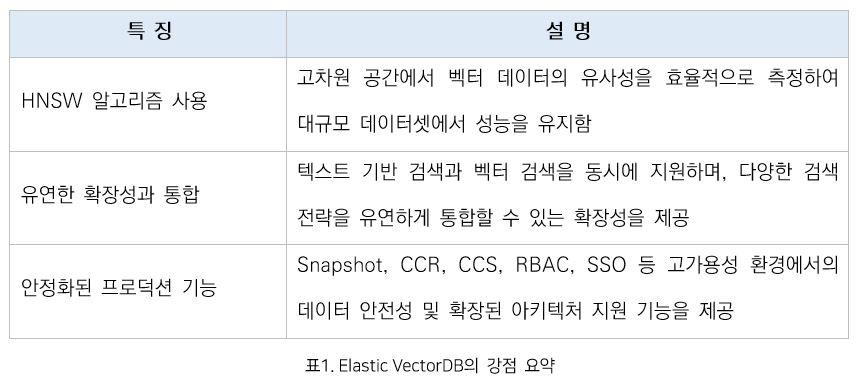
HNSW 알고리즘 사용
Elasticsearch는 벡터 데이터를 효율적으로 처리하기 위해 HNSW(계층적 소형 세계 그래프) 알고리즘을 채택하고 있다. HNSW 알고리즘은 벡터 데이터를 고차원 공간에 매핑하여 인덱싱하고, 데이터 간의 유사성을 빠르게 측정할 수 있도록 설계되었다. 특히, 대규모 데이터셋에서도 검색 성능을 유지하며, 정확한 검색 결과를 제공한다. 이 알고리즘은 Elasticsearch가 대규모 벡터 데이터베이스로서 기능할 수 있는 기반을 마련해 준다. HNSW는 검색 쿼리와 인덱싱 작업에서의 성능 저하를 최소화하면서도, 높은 정확도를 유지하기 때문에 대규모 데이터 환경에서 매우 유용하다.
유연한 확장성과 통합
Elasticsearch의 가장 큰 강점 중 하나는 유연한 확장성이다. 클러스터 단위의 분산 환경에서 작동하도록 설계된 Elasticsearch는 수십억 개의 벡터 데이터를 처리하는 데 최적화되어 있어, 데이터가 급격히 증가하는 상황에서도 효율적으로 대응할 수 있다.
Elasticsearch는 텍스트 기반 검색과 벡터 검색을 동시에 지원해 복합적인 검색 요구를 하나의 플랫폼에서 처리할 수 있다. 특히, Reciprocal Rank Fusion(RRF)을 통한 하이브리드 검색, Rerank 모델의 연계, 그리고 머신러닝 모델 내재화를 통해 다양한 검색 전략을 유연하게 통합할 수 있다.
Elasticsearch의 확장성과 통합은 고급 검색 애플리케이션 서비스에서 성능과 기능의 균형을 유지하며, 아키텍쳐의 복잡성을 줄여주는 등의 효율적인 측면에서도 매우 중요하다.
안정화된 프로덕션 기능
Elasticsearch는 데이터 백업 및 복구인 Snapshot, 클러스터 간 동기화 기능인 CCR(Cross-Cluster Replication), 클러스터 간 검색 기능인 CCS(Cross-Cluster Search), RBAC(Role-Based Access Control), SSO(Single Sign-On) 등의 프로덕션 기능을 제공한다. 이러한 프로덕션 기능은 고가용성 환경에서 데이터의 안전성을 보장하며 CCR과 CCS를 통해 여러 클러스터에서 실시간으로 데이터를 복제하고 검색할 수 있게 하여, 확장된 아키텍쳐 설계에서의 중요한 역할을 한다. 이러한 기능들은 단순히 벡터 검색을 넘어서, 실제 운영 환경에서 Elasticsearch의 활용도를 크게 높여준다.
Elasticsearch 벡터 검색 성능 최적화
Elasticsearch에서 벡터 검색의 성능을 극대화하기 위해서는 여러 가지 최적화 기법을 적용하는 것이 중요하다.
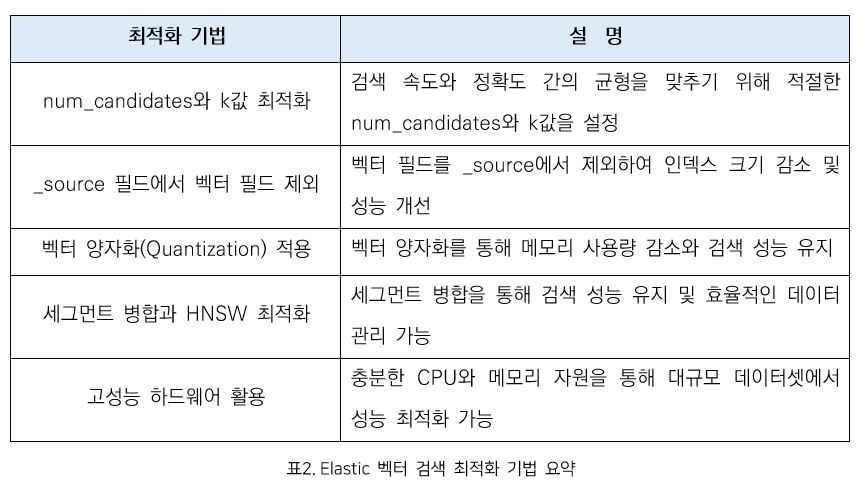
num_candidates와 k 값 최적화
num_candidates는 k값의 1.5배로 설정하는 것이 k-NN 검색의 성능과 정확도 최적화에 꽤 괜찮은 접근 방법이다. 이 설정은 초기 튜닝 과정에서 시간을 절약할 수 있으며, Elasticsearch의 다양한 벤치마킹 테스트에서도 재현율과 지연율 사이에서 균형을 이루는 최적의 값으로 나타났다. num_candidates는 검색 쿼리 실행 시 고려되는 후보 벡터의 수를 의미하며, k는 반환되는 유사한 결과의 수를 결정한다. 이 두 파라미터를 적절히 조정하면 검색 속도와 정확도 간의 최적의 균형을 찾는 데 도움이 된다.
_source 필드에서 벡터 필드 제외
성능 최적화를 위해 벡터 필드를 _source에서 제외하는 것도 좋은 방법이다. 벡터 데이터를 _source 필드에 저장하면 인덱스 크기가 커지고, 검색 시 불필요한 데이터가 로드될 수 있어 성능이 저하된다. 벡터 필드를 _source에서 제외하면 메모리 사용량과 검색 속도가 크게 개선된다. 다만, _source 필드를 제외하면 이후에 reindex를 할 수 없으므로, 이 점을 고려해 다양한 대안을 준비해야 한다.
벡터 양자화(Quantization) 적용
Elasticsearch는 8.15버전 기준 최대 4096차원까지 벡터를 지원하지만, 이를 그대로 적용할 경우 검색 속도 저하와 메모리 사용량 증가가 발생한다. 벡터 양자화는 메모리 사용량을 줄이면서도 검색 정확도와 성능을 유지하는 중요한 기법이다.
element_type: 벡터를 인코딩하는 데 사용되는 데이터 유형을 지정하며, 특히 bit 타입은 차원당 단일 비트를 인덱싱한다. 이 방식은 매우 고차원 벡터 또는 비트 벡터를 사용하는 모델에 유용하다. 참고로, bit 타입을 사용할 때 차원 수는 8의 배수여야 한다.
index_options: HNSW 알고리즘에서 데이터 구조를 구축하는 방식을 정의한다. int8_hnsw와 int4_hnsw가 지원되며, 각각 벡터를 1바이트 또는 반바이트 정수로 양자화한다. int4 양자화는 벤치마킹 결과 메모리 사용량을 최대 87%까지 줄일 수 있었으며, 인덱싱할 때 차원 수가 짝수여야 한다.
세그먼트 병합과 HNSW 알고리즘 최적화
인덱스 세그먼트의 수를 줄이는 것도 성능 최적화에 필수적이다. 세그먼트가 많을수록 검색 속도가 느려질 수 있으며, 특히 HNSW 알고리즘은 각 샤드 내에서 생성된 인덱스를 기반으로 작동하므로 세그먼트가 많을 경우 검색 효율이 떨어질 수 있다. 이를 줄이기 위해 정기적으로 세그먼트 병합을 수행하는 것이 좋다. 세그먼트 병합은 Elasticsearch의 자동 관리 기능을 통해 이루어지지만, 수동으로 관리하는 것도 성능 유지에 도움이 될 수 있다.
고성능 하드웨어 활용
Elasticsearch의 벡터 검색 성능을 극대화하기 위해 고성능 하드웨어를 사용하는 것도 매우 중요하다. 충분한 CPU와 메모리 자원을 확보하면 검색 속도를 크게 개선할 수 있으며, 대규모 데이터셋을 처리할 때 성능 저하를 최소화할 수 있다. 이러한 하드웨어 최적화는 전체 시스템의 효율성을 높이는 데 기여한다.
마치며- 향후 발전 가능성 및 결론
Elastic의 솔루션인 Observability와 Security 분야에서 독창적인 Elastic AI Assistant 기능 도입과 머신러닝 기술 통합을 통해 정교한 데이터 관리 솔루션을 제공한다. 또한, 루씬 엔진의 커미터 다수가 Elastic의 직원으로 활동하며, 내부 매커니즘의 지속적인 최적화를 이루고 있다. AI 기술 변화에 따른 발빠른 기술 도입의 예로는 ELSER(Elastic Learned Sparse Encoder)와 같은 혁신적인 자체 모델이 있으며, ZStandard 데이터 압축 기법은 철저한 검토 끝에 Elasticsearch 8.15 버전에서 도입되어 높은 압축률과 효율적인 CPU 사용으로 대규모 데이터셋을 빠르고 정확하게 처리할 수 있도록 돕는다. 이러한 기술들은 Elastic의 유연한 확장성을 더욱 강화하고, 다양한 산업 분야에서의 활용도를 높이는 데 기여하고 있다.
또한, 국내에서는 금융권과 대기업(S사, L사 등)에서 Elastic을 활용한 RAG 도입 사례가 지속적으로 증가하고 있으며, 해외에서는 Cisco, Adobe, IBM, Stack Overflow와 같은 글로벌 기업들이 이미 Elastic을 활용하여 사용 중이다.
이러한 발전 가능성은 Elastic이 벡터 데이터베이스 분야에서 지속적으로 핵심적인 역할을 할 것임을 보여주며, 기업들이 데이터를 효과적으로 활용하는 데 있어서 주요한 도구로 자리잡을 것이다.
에스코어는 오픈소스 전문가 집단으로, 국내 최초의 Elastic MSP(Managed Service Provider)이다. Elastic Contributor를 포함한 국내 최고 수준의 전문가들이 모여 맞춤형 기술 조언, 차별화된 문제 해결, 정기점검 등으로 구성된 케어팩(Carepack) 서비스를 원스톱으로 제공한다.
# References
- https://www.elastic.co/kr/blog/why-technology-leaders-need-vector-search
- https://www.elastic.co/kr/what-is/vector-search
- Malkov, Yu A., and Dmitry A. Yashunin. "Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs." IEEE transactions on pattern analysis and machine intelligence 42.4 (2018): 824-836.
- https://www.elastic.co/kr/subscriptions
- https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-knn-search.html
- https://www.elastic.co/search-labs/blog/bit-vectors-in-elasticsearch
- https://www.elastic.co/search-labs/blog/simplifying-knn-search
- https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-search-speed.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html
- https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-elser.html
- https://www.elastic.co/kr/blog/introducing-elastic-ai-assistant
- https://facebook.github.io/zstd/
- https://www.elastic.co/customers

안상희 프로
소프트웨어사업부 OSS사업팀
Elastic Stack 기술지원 및 컨설팅 제공 전문가이며, 삼성그룹의 오픈소스 기반 메일 검색, 금융권 Elastic 도입 등 다양한 Elastic 프로젝트에서 풍부한 경험을 통해 오픈소스, 최적화, SRE, 컨설팅 분야에 깊은 관심을 갖고 활동하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.