들어가며
클라우드 컴퓨팅의 아키텍처는 그 내부 구성 요소(Component)와 이에 포함된 하위 구성 요소(Subcomponent)가 명확히 표현되어야 한다. 클라우드 컴퓨팅이 서버, 데이터베이스, 소프트웨어, 가상 스토리지, 네트워킹 등 수많은 IT 서비스를 제공한다는 점에서 아키텍처는 중요하다. 그리고 데이터를 제한 없이 보관하고 액세스하게 해주는 가상 플랫폼이라는 점에서도 중요하다.
클라우드 아키텍처는 결국 레이아웃이며 클라우드 컴퓨팅에 필요한 구성 요소와 기술을 연결한다. 예를 들어, Google Cloud의 경우 ‘Cloud Build’가 빌드를 실행하는 서비스인데, 이는 다양한 저장소 또는 ‘Cloud Storage’ 공간에서 소스코드를 가져온다. 또한, 사양에 맞게 빌드를 실행하며, ‘도커 컨테이너’ 또는 ‘자바 아카이브’ 등의 아티팩트(Artifact, 소프트웨어 개발 중에 만들어지는 다양한 유형의 부산물)를 생성한다.
여기서 도커 컨테이너는, 애플리케이션과 그 실행 환경을 패키징하여 일관성 있게 배포하고 실행하게 하는 기술로서, ‘컨테이너’를 만드는 데 사용되는 읽기 전용(Read-only) 템플릿인 ‘도커 이미지’를 실행한 상태를 의미한다. 컨테이너는, 커널(OS의 핵심 프로그램이자 시스템의 모든 부분을 완전히 제어하여 OS의 다른 부분 및 애플리케이션 수행에 필요한 서비스를 제공하는 구성 요소)을 공유하는 방법으로 호스트 OS(Operating System) 하나에서 여러 OS를 가상화한 형태를 뜻한다. 또한, 자바 아카이브는 여러 개의 자바 클래스 파일(Java Class File, 자바 가상 머신에서 실행 가능한 자바 바이트코드를 포함하는 컴퓨터 파일)과, 클래스들이 이용하는 관련 리소스(텍스트, 그림 등) 및 메타 데이터를 하나의 파일로 모아, 자바 플랫폼에 애플리케이션이나 라이브러리를 배포하기 위한 소프트웨어 패키지 파일 포맷이다.
클라우드 컴퓨팅 아키텍처의 패러다임
클라우드 컴퓨팅 아키텍처는 이른바 ‘SOA(Service Oriented Architecture)’와 ‘EDA(Event Driven Architecture)’의 결합이다. 이 둘은 독립적이나 상호보완적이다.
SOA는 대규모 컴퓨터 시스템을 구축할 때 활용되는 개념으로, 업무상의 일 처리에 해당하는 소프트웨어 기능을 ‘서비스’로 판단하고 그 서비스를 네트워크상에서 연동하여 시스템 전체를 구축하는 방법론이다. SOA는 서비스 인터페이스에 의해 소프트웨어 구성 요소의 재사용과 상호 운용을 가능하게 하는 방법을 정의하는데, 여기서 서비스는 공통 인터페이스 표준과 아키텍처 패턴을 사용하므로 새로운 애플리케이션에 신속하게 통합된다. 이로써 애플리케이션 개발자는 기존의 기능을 재개발 또는 복제하거나 기존 기능을 연결하거나 상호 운용성을 제공하는 방법을 알아야 했던 수고를 덜게 된다. SOA의 각 서비스는 완벽한 개별적 비즈니스 기능(예를 들면 고객의 신용 확인, 월별 융자 상환액 계산, 모기지 신청 처리 등)의 실행에 필요한 코드와 데이터를 구현한다.
EDA는 ‘이벤트’를 게시, 소비 또는 라우팅(Routing, 어떤 네트워크 안에서 통신 데이터를 보낼 때 최적의 경로를 선택하는 과정)하는 분리된 소형 서비스로 구축된 현대적인 아키텍처 패턴인데, 여기서 이벤트는 상태 변경 또는 업데이트를 나타낸다. 예를 들면 장바구니에 들어간 품목, 스토리지 시스템에 업로드된 파일, 배송 준비된 주문 등이 이벤트에 해당된다. 결국 이벤트는 상태(예: 주문 내의 품목 이름, 가격, 주문 수량 등)를 전달하거나 관련 정보를 조회하는 데 필요한 식별자(예: “주문 OOO이 배송되었습니다” 등)를 포함한다.
SOA와 EDA의 클라우드 아키텍처 적용 사례는 [표1]과 같다.

이상의 사례를 보면, 고객 또는 센서에 의해 발생한 이벤트를 이벤트 브로커에 전달한 후 각각의 SOA 단계를 거쳐 (필요에 따라 고객에게 전달하고) 완료되는 형태로 클라우드 아키텍처를 적용한 예시가 도출된다.
이러한 클라우드 컴퓨팅 아키텍처는 사용자(End User) 및 기관에 확장성, 유연성 (또는 탄력성) 및 경제성 등을 제공하기 위해 설계되었다. 확장성은 사용자 수와 트래픽이 점차 증가하면서 시스템이 응답성을 유지하는 능력이다. 사용되는 대부분의 B2B 및 B2C 애플리케이션은 안정성, 고성능 및 가동 시간을 보장하기 위해 확장성이 필요하다. 사용자는 몇 가지 사소한 구성 변경과 버튼 클릭만으로 몇 분 만에 클라우드 시스템을 쉽게 확장 또는 축소한다. 대부분 이는 서버, 클러스터 및 네트워크 수준에서 스케일 팩터가 적용된 클라우드 플랫폼으로 자동화해 엔지니어링 인건비를 절감하게 되므로 경제성과도 직결된다. 탄력성은 단기 버스트(Burst, 온프레미스 인프라가 피크 용량에 도달할 때마다 클라우드 컴퓨팅 리소스를 사용하는 구성 방식) 또는 부하가 순간적으로 급증하는 동안 응답을 유지하는 시스템의 능력이다. 탄력성 문제에 정기적으로 직면하는 시스템의 사례는 티켓팅 애플리케이션, 경매 시스템 등이다. 2020년에 티켓팅 애플리케이션 회사들은 매우 많은 클라우드 용량이 필요할 때 라이브 스트리밍을 위해 AWS(Amazon Web Services)에 의존했다. 예측하기 어려운 워크로드를 경험하지만 사전 계획된 확장을 원하지 않는 기업은 유지관리 비용이 낮은 퍼블릭 클라우드에서 탄력적인 솔루션을 찾는다.
아키텍처의 기능적 구성 – 프론트엔드와 백엔드
클라우드 컴퓨팅 아키텍처는 크게 프론트엔드와 백엔드로 나뉜다. 프론트엔드는 버튼, 체크박스, 그래픽, 문자 메시지 등 사용자에게 보이는 시각적 요소이다. 사용자는 이러한 시각적 요소로써 애플리케이션과 상호 작용을 한다. 백엔드는 사용자의 애플리케이션 데이터를 저장하고 처리한다. 프론트엔드와 백엔드는 네트워크, 주로 인터넷에 의해 소통을 한다. [그림1]은 클라우드 컴퓨팅 아키텍처의 구성을 단순하게 도식화한 표현이다.

1. 프론트엔드
프론트엔드는 클라우드 기반 서비스에 필요한 애플리케이션과 인터페이스를 제공한다. 이는 ‘클라이언트 사이드(Client’s Side) 애플리케이션’으로 구성되며 결국 Google Chrome 등의 웹 브라우저나 Mobile App.을 의미하는데 Fat (또는 Thick) Client, Thin Client, Mobile 등으로 분류 가능하다. 여기서 Fat Client는 중앙 서버와 독립하여 풍부한 기능을 제공하는 클라이언트-서버 구조나 네트워크의 컴퓨터(클라이언트)이다. 반면, Thin Client는 자신의 계산 역할을 충족시키기 위해 다른 일부 컴퓨터(서버)에 크게 의존하는 컴퓨터나 프로그램이다.
이러한 프론트엔드 구성 요소를 ‘클라우드 인프라’로 통칭하기도 하는데 데이터 스토리지, 서버, 가상 소프트웨어 등 하드웨어와 소프트웨어 구성 요소를 포함한다. 또한, 각 사용자가 개별 작업을 수행하도록 GUI(Graphic User Interface)를 제공한다.
AWS의 경우, 다음 [표 2]의 세 가지 주요 컴퓨터 언어가 사용자와 프론트엔드의 상호 작용 방식에 영향을 미친다.

JavaScript는 페이지의 변경을 트리거하고 새 정보를 표시한다. 즉, 프론트엔드는 캘린더를 표시하거나 사용자가 유효한 이메일 주소를 입력했는지 확인하는 등의 기본적인 사용자 상호 작용 (또는 요청) 처리가 가능하다.
2. 백엔드
백엔드는, 프론트엔드에서 애플리케이션을 실행하는 모든 프로그램의 모니터링 역할을 담당한다. 이에 따라 수많은 데이터 저장 시스템과 서버를 보유하고, 전체 클라우드 컴퓨팅 아키텍처에서 매우 중요하고 큰 부분을 차지한다. 그 구성은 [표 3]와 같다.

아키텍처의 주요 세부 구성 요소
1. 하이퍼바이저
모든 사용자에게 가상 운영 플랫폼(Virtual Operating Platform)을 제공하는 ‘가상 머신(VM, Virtual Machine)’ 모니터로서, 가상 머신과 기본적인 실제 하드웨어 간의 조정을 위해 존재하며 클라우드에서 게스트 OS를 관리한다. 여기서 가상 머신은 실제 컴퓨터의 가상 표현 또는 에뮬레이션이다. 이를 종종 게스트라고 하며, 이를 실행하는 실제 시스템을 호스트라 한다. 즉, VM은 컴퓨팅 환경의 소프트웨어 구현으로, 그 위에 OS와 애플리케이션이 설치 및 실행된다. 이러한 가상 머신 기술은 가상 서버, 가상 서버 인스턴스(Virtual Server Instance), 가상 프라이빗 서버(Virtual Private Server) 등으로 불린다.
하이퍼바이저는 소프트웨어와 하드웨어로 구성된 별도의 VM을 백엔드에서 실행하며 주요 목적은 자원의 분할 및 할당이다. 애플리케이션, 서버, 스토리지, 네트워킹을 포함한 모든 서비스를 나타내는 하이퍼바이저 생성을 위해 가상화 기술을 사용하는 런타임 클라우드가 서비스 실행 환경을 제공하며 서비스 작업 실행 및 관리를 수행하는 OS 역할을 한다.
2. 관리 소프트웨어
클라우드의 성능을 높이기 위해 다양한 방식으로 클라우드 운영을 관리하고 모니터링하는 역할을 담당한다. 예를 들면 사용량 모니터링, 규정 준수 감사, 재난 감시 관리, 비상시 계획, 재해 복구(DR, Disaster Recovery) 등의 작업을 수행한다.
재해 복구의 경우, 그 목표는 워크로드 복구 및 다운타임의 완전히 방지로서 측정 기준은 [표4]의 RTO와 RPO이다.
이러한 재해 복구 이전에 서버 이중화에 의한 ‘HA(High Availability)’가 우선 필요한데, 이는 IT 서비스의 안정성을 유지하기 위해 리소스를 이중 또는 그 이상으로 구성하는 방식이다. 즉, 운영하는 서비스가 연속성을 가지고 운영되도록 준비하는 방법이다. 유형은 크게 2가지로 나뉘는데, 서버가 2대라면 한 시스템만 운영하고 다른 하나는 대기 상태로 두는 Active-Standby 방식, 2대의 서버로 동시에 운영하는 Active-Active 방식이다. 이러한 이중화로 특정 시스템, 컴포넌트의 문제 발생 시 빠르게 해결 가능하다.
AWS의 경우 HA를 위해 다중 리전 아키텍처에 의해 99.99% 이상의 가용성 달성이 가능하다고 한다. 그리고 각 리전은 여러 개의 ‘가용 영역(AZ, Availability Zone)’을 사용한다. 리전은 AWS가 전 세계에서 데이터 센터를 클러스터링하는 물리적 위치를 의미하고, 논리적 데이터 센터의 각 그룹을 가용 영역이라고 한다. 각 AWS 리전은 지리적 영역 내에서 격리되고 물리적으로 분리된 최소 3개의 AZ로 구성된다. 즉, AZ는 AWS 리전의 중복 전력, 네트워킹 및 연결이 제공되는 하나 이상의 개별 데이터 센터이다. AZ는 다른 모든 AZ와 수 킬로미터에 상당하는 유의미한 거리를 두고 물리적으로 분리되었는데, 다만 리전 내 모든 AZ는 서로 100킬로미터 이내의 거리에 위치한다.
3. 배포(Deployment) 소프트웨어
클라우드 서비스를 실행하는 데 필요한 모든 필수 설치 및 컨피규레이션(Configuration)으로 구성되며 SaaS(Software as a Service), PaaS(Platform as a Service), IaaS(Infrastructure as a Service) 등 모든 클라우드 서비스 배포를 수행한다.
SaaS에서는 클라우드 공급자가, 구독 방식으로 직접 구매 가능한 애플리케이션이나 소프트웨어 등의 최종 제품을 제공한다. 이 서비스의 일부로 고객은 소프트웨어 환경에 대한 제어권을 유지하지만 장비는 유지하지 않는다. 이 모델은 서비스 제공업체가 제공하고 유지관리하는 클라우드 기반 애플리케이션 서비스이므로, 최종 사용자가 로컬에서 소프트웨어를 배포할 필요가 없다.
PaaS 모델에서는 코드와 애플리케이션을 배포하는 클라우드 공급자로부터 사전 구축된 플랫폼이 제공된다. 결국 PaaS는 애플리케이션의 구축, 실행 및 관리에 필요한 플랫폼을 제공하는 서비스로서, 개발자가 애플리케이션 코드를 작성하면 실행 환경, 데이터베이스, 웹 서버 등의 기술적인 측면을 고려하지 않고도 애플리케이션을 배포하게 해준다. AWS Elastic Beanstalk는 PaaS의 전형적인 예시이다.
IaaS는 서버, 스토리지, 네트워크 등을 포함하여 종량제 방식으로 클라우드 공급자가 제공하는 IT 인프라로 구성된다. IaaS는 프로비저닝(Provisioning, 사용자 요구에 맞게 시스템 자원을 할당, 배치, 배포해 두었다가 필요 시 시스템을 즉시 사용 가능한 상태로 미리 준비)한 서비스에 액세스 가능하고 일부는 루트 수준 액세스도 허용된다. Amazon EC2(Elastic Compute Cloud)가 대표적인 예시이다.
SaaS, PaaS, IaaS 외에 최근에는 AaaS(Authentication as a Service), DaaS(Desktop as a Service) 등 새로운 클라우드 서비스 모델도 제시된다. AaaS는 MFA(Multi-Factor Authentication, 두 가지 이상 별도의 증거 부분을 인증 메커니즘에 성공적으로 제시한 후에만 사용자에게 접근 권한이 주어지는 컴퓨터 접근 제어 방식)와 SSO(Single Sign-On) 등의 서비스를 제공한다. DaaS는 Amazon Workspaces, Azure Virtual Desktop처럼 클라우드에서 매니지드 가상 데스크톱을 제공하는 서비스이다.
4. 네트워크
프론트엔드와 백엔드를 연결하여 모든 사용자가 클라우드 리소스에 액세스하게 한다. 사용자가 경로(Route)와 프로토콜을 연결하고 Customize하도록 지원하며, 클라우드 컴퓨팅 플랫폼에서 호스팅되는 가상 서버이다. 이는 인터넷, 인트라넷 또는 인터클라우드 등으로 분류된다.
네트워크와 관련하여, 로드 밸런싱은 애플리케이션을 지원하는 리소스 풀 전체에 네트워크 트래픽을 균등하게 배포하는 방법이다. 최신 애플리케이션은 수많은 사용자를 동시에 처리하고 정확한 텍스트, 비디오, 이미지 및 기타 데이터를 빠르고 안정적으로 각 사용자에게 제공해야 한다. 이렇게 많은 양의 트래픽 처리를 위해 대부분의 애플리케이션에는 데이터가 중복되는 리소스 서버가 많다. 이 때 로드 밸런서는 사용자와 서버 그룹 사이에 위치하며 보이지 않는 촉진자 역할을 하여 모든 리소스 서버가 동일하게 사용되도록 하는 디바이스이다. 이러한 로드 밸런서는 시스템의 일부 결함, 고장이 발생하더라도 정상적 또는 부분적인 기능을 수행하도록 설계된 장애 방지 시스템이다.
5. 클라우드 스토리지
인터넷을 활용하여 여러 사용자가 어디서나 데이터를 저장 및 액세스 가능하며, 런타임 시 Scalable하고 자동으로 액세스된다. 즉, 웹으로 클라우드 스토리지에서 데이터 수정 및 검색이 가능하다. 이는 일반적으로 퍼블릭 클라우드, 프라이빗 클라우드, 커뮤니티 클라우드, 하이브리드 클라우드 등의 구성으로 배포된다. 여기서 커뮤니티 클라우드는 특정 목적의 커뮤니티에 소속된 다수 기관이 사용하는 클라우드 배포 모델을 의미한다. 하이브리드 클라우드는 퍼블릭 클라우드와 온프레미스 데이터 센터 또는 ‘에지(Edge, 네트워크의 클라이언트 또는 디바이스에게 컴퓨팅 파워를 분산해주는 기술 구조)’ 위치를 포함한 프라이빗 클라우드와 같은 서로 다른 환경에서 컴퓨팅, 스토리지, 서비스의 조합을 사용하여 애플리케이션을 실행하는 혼합 컴퓨팅 환경을 의미한다.
6. 데이터베이스
SQL(Structured Query Language), NOSQL(Not Only SQL) 데이터베이스 등 데이터를 조직화, 저장, 관리, 검색하는 시스템을 의미한다. 데이터베이스 서비스의 예로는 Amazon RDS(Relational Database Service), Microsoft Azure SQL 데이터베이스 및 Google Cloud SQL 등이 있다.
7. 분석
데이터 웨어하우스(Data Warehouse, 사용자의 의사결정에 도움을 주기 위해 기간 시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터베이스), 비즈니스 인텔리전스(Business Intelligence, 사업 전략을 효율적/효과적으로 지원하여 각 조직의 구성원이 적시에 의사결정을 하도록 지원하는 정보 체계), 기계 학습(Machine Learning)과 Deep Learning 등 클라우드의 데이터에 대한 분석 기능을 제공하는 구성 요소이다.
특히, 생성형(Generative) 인공 지능(AI, Artificial Intelligence)은 비즈니스에 엄청난 가치를 부여하고 업무 방식을 근본적으로 변화시킬 잠재력이 있다고 여겨진다. 이러한 획기적인 기술은 우리 삶의 여러 측면에, 세계 경제의 거의 모든 부문에 이미 존재한다. 또한 애플리케이션이나 산업에 관계없이 생성형 AI의 영향은 클라우드 컴퓨팅 생태계에서 가장 뚜렷하다. 기업이 클라우드 운영에 이 기술을 활용하려고 서두르기 때문에, 생성형 AI 모델을 안전하고 책임감 있게 배포하려면 먼저 네트워크 연결 요구 사항과 위험에 대한 이해가 필요하다.
LLM(Large Language Model)은 매우 크기 때문에 이를 Training하려면 방대한 양의 데이터와 초고속 컴퓨팅이 필요하며 데이터 세트가 클수록 컴퓨팅 성능에 대한 수요도 더 커진다. 퍼블릭 클라우드 환경에서 생성형 AI 모델을 교육하기 위한 주요 연결 요구 사항 중 하나는 데이터 세트의 스케일에 대한 적절한 액세스이며, 이러한 LLM을 교육하는데 필요한 막대한 처리 능력은 해결해야 할 과제의 일부일 뿐이다. 이와 함께 고려해야 할 다른 요소는, 퍼블릭 클라우드에서 전송되는 데이터의 주권, 보안 및 개인 정보 보호 요구 사항의 관리 등이다.
아키텍처의 3단계 레이어 분류
클라우드 컴퓨팅 아키텍처의 작동 방식을 좀 더 쉽게 이해하기 위해, 다른 각도에서 레이어 단위로 분류하는 방법이 유용하다. 아래는 단순하게 하드웨어, 가상화, 애플리케이션 및 서비스의 3가지 레이어로 분류한 경우이다.
1. 하드웨어
클라우드를 작동하게 하는 서버, 스토리지, 네트워크 장비 및 기타 하드웨어 등이다.
2. 가상화
물리적 컴퓨팅 및 스토리지 리소스의 가상 표현을 생성하는 추상화 레이어다. 이로써 여러 애플리케이션이 동일한 리소스를 사용하게 된다. 이러한 가상화 기술은 앞서 언급한 하이퍼바이저에 의해 하드웨어를 에뮬레이션하는 방법으로, 가상 이미지마다 게스트 OS를 사용해야 한다. 즉, 온프레미스에 있건 혹은 클라우드에 있건, 가상 머신에서는 하이퍼바이저를 활용하여 물리적 하드웨어를 가상화한다. 그리고 각각의 VM에는 애플리케이션, 이와 연관된 라이브러리 및 종속 항목과 함께 OS가 실행해야 하는 하드웨어의 가상 사본인 게스트 OS가 포함된다.
한편 컨테이너는, 앞서 언급했듯이 ‘커널’을 공유하는 방법으로서 호스트 OS 하나에서 여러 OS를 가상화한다. [그림 2]는 ‘커널’이 애플리케이션을 하드웨어에 연결한 모습이다.
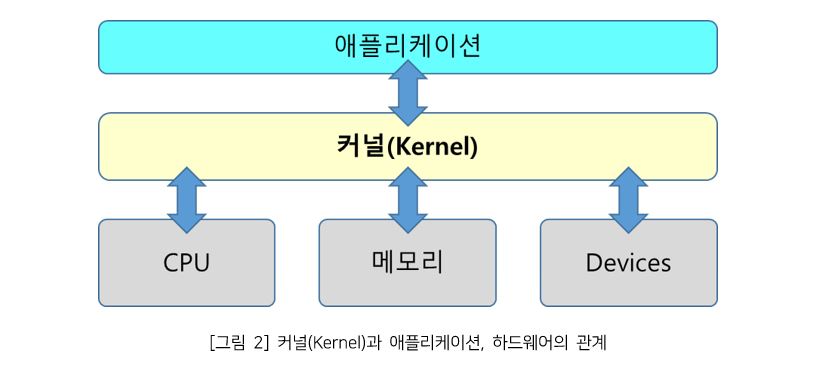
커널(Kernel)과 애플리케이션, 하드웨어의 관계
컨테이너는 애플리케이션의 코드, 라이브러리 및 기타 종속 구성 요소를 포함하는 소프트웨어 코드 패키지이다. 컨테이너化로 애플리케이션을 이동 가능하게 하여 모든 디바이스에서 동일한 코드 실행이 가능하다. 컨테이너는 OS를 가상화하여 애플리케이션이 모든 플랫폼에서 독립 실행되게 함으로써 하드웨어 리소스를 효율적으로 사용한다. 기반 하드웨어를 가상화하는 대신, 컨테이너가 OS(일반적으로 Linux)를 가상화하므로, 각각의 개별 컨테이너에는 오직 애플리케이션 및 이의 라이브러리와 종속 항목만 포함된다.
컨테이너化된 애플리케이션의 자동 디플로이, 스케일링 등을 제공하는 관리 시스템, 즉 컨테이너 오케스트레이션 플랫폼으로 잘 알려진 소프트웨어가 쿠버네티스로서, 오픈 소스 기반으로 널리 사용되며 FaaS(Function as a Service)라고도 하는 서버리스의 패러다임을 더욱 향상시켰다. 쿠버네티스는 원래 구글에 의해 설계되었는데, 현재는 리눅스 재단 산하에 설립된 CNCF(Cloud Native Computing Foundation)에서 관리 중이다. 목적은 여러 클러스터의 호스트 간에 애플리케이션 컨테이너의 배치, 스케일링, 운영을 자동화하기 위한 플랫폼을 제공하기 위함이다. 이는 도커를 포함하여 일련의 컨테이너 도구들과 함께 동작하는데, 도커는 리눅스의 응용 프로그램들을 프로세스 격리 기술들을 사용해 컨테이너로 실행하고 관리하는 오픈소스 프로젝트이다. 도커 컨테이너는 소프트웨어를, 애플리케이션 실행에 필요한 모두를 포함하는 완전한 파일 시스템 안에 패키징한다. 여기에는 코드, 런타임, 시스템 도구, 시스템 라이브러리 등 서버에 설치되는 무엇이든 포함한다. 이는 실행 중인 환경에 관계 없이 언제나 동일하게 실행될 것을 보증한다.
3. 애플리케이션 및 서비스
이는 프론트엔드 사용자 인터페이스의 요청을 조정하고 지원하며, 리소스 할당에서 애플리케이션 개발 도구, 웹 기반 애플리케이션에 이르기까지 클라우드 서비스 모델을 기반으로 다양한 서비스를 제공하는 레이어다.
아키텍처의 5단계 레이어 분류
클라우드 컴퓨팅 아키텍처의 레이어를 5가지로 분류한다면 물리적 서버, 컴퓨팅 리소스, 스토리지 리소스, 하이퍼바이저, 가상 머신으로 분류함이 적절하겠다. [그림3]은 AWS의 사례에 근거한 클라우드 레이어 아키텍처이다. 여기서 BIOS(Basic Input Output System)는 컴퓨터에서 전원을 켜면 맨 처음 컴퓨터의 제어를 맡아 가장 기본적인 기능을 처리해 주는 프로그램이다.

클라우드 컴퓨팅 과제의 아키텍처 등 심의 체크리스트
아키텍처의 구성 요소 및 레이어 분류에 근거하여, 클라우드 컴퓨팅의 도입 등 과제 심의시 활용할 체크리스트는 크게 중복성, 개발 표준, 아키텍처 적정성, 개인 정보 보유 여부 등의 범주로 분류하는 방안을 하나의 예시로 활용 가능하다. [그림4]는 이러한 4가지 범주에 따라 세부 체크리스트를 정리한 사례이다.

마치며
클라우드 컴퓨팅 아키텍처에서 아키텍처라는 단어는 ‘아키텍트(Architect)’에서 파생된 용어로 건축학, 건축 양식 등을 의미하는데(‘아키텍트’의 원어는 ‘Master Builder’라는 뜻이다.) 클라우드 컴퓨팅에서도 단순히 설계의 결과물만을 의미하지는 않는다. 원칙적인 의미의 아키텍처를 생각하면 전체 시스템의 구성과 동작 원리를 나타내는 일종의 방법, 기준, 산출물 등으로 이해되는데, 좀 더 복잡성을 보이는 클라우드 컴퓨팅의 영역에서 보면 아키텍처의 동적인 요소가 많이 인식된다. 즉, 환경 변화에 따라 최적화를 위해 움직이는 전략적인 의미로 확장 가능하다.
기업 수준의 전략이나 사업 전략 등은 외부 환경 변화에 따라 다양한 시나리오를 가정하고 이에 따른 대응 방안과 과제를 수립하는데, 아키텍처 역시 그러한 관점을 참고할 필요가 있겠다. 특정 과제의 클라우드 컴퓨팅 아키텍처가 하나의 완벽한 정답으로 존재하리라 기대하기 보다는, 변화하는 시간과 공간에서 다양한 선택지가 제시되고 이들 중 최적의 의사결정을 하며 이후 상황에 따라 능동적으로 유연한 대응을 수행함이 적절하다.
경영 전략의 경우와 마찬가지로 아키텍처 또한 인적 요소가 중요하다. 특정 과제를 기획하고 실행함에 인적 요소의 중요성은 설명이 필요 없듯이 아키텍처 또한 최종 결과물이 나오기까지 그 인적 요소에 따라 계속 변화하고 성공과 실패가 갈린다. 거듭 강조하자면, 비즈니스의 시간과 공간은 변하기 마련이고 이를 다루는 사람은 저마다 다르다. 중요한 요소를 적절히 관리하고 최선을 추구함은 클라우드 컴퓨팅의 아키텍처에 대해서도 마찬가지이다.
# References
- https://www.simplilearn.com/tutorials/cloud-computing-tutorial/cloud-computing-architecture
- https://www.simplilearn.com/tutorials/cloud-computing-tutorial/what-is-cloud-computing
- https://cloud.google.com/learn/what-is-cloud-architecture?hl=ko
- https://cloud.google.com/build/docs/overview?hl=ko
- https://www.ibm.com/kr-ko/topics/virtual-machines
- https://www.ibm.com/kr-ko/topics/soa
- https://aws.amazon.com/ko/what-is/eda/
- https://www.kcloudnews.co.kr/news/articleView.html?idxno=10921
- https://aws.amazon.com/what-is/cloud-bursting/?nc1=h_ls
- https://aws.amazon.com/ko/compare/the-difference-between-frontend-and-backend/
- https://www.geeksforgeeks.org/architecture-of-cloud-computing/
- https://m.blog.naver.com/n_cloudplatform/222902525445
- https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/rel_fault_isolation_select_location.html
- https://aws.amazon.com/ko/about-aws/global-infrastructure/regions_az/
- https://www.samsungsds.com/kr/cloud-glossary/paas.html
- https://blog.naver.com/PostView.naver?blogId=ki630808&logNo=221967460147
- https://www.akamai.com/ko/blog/cloud/what-is-cloud-architecture
- https://aws.amazon.com/ko/what-is/load-balancing/
- https://aws.amazon.com/ko/blogs/tech/disaster-recovery-dr-architecture-on-aws-part-i-strategies-for-recovery-in-the-cloud-1/
- https://cloud.google.com/learn/what-is-hybrid-cloud?hl=ko
- https://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=039155-1
- http://www.opennaru.com/cloud/virtualization-vs-container/
- https://aws.amazon.com/ko/compare/the-difference-between-containers-and-virtual-machines/
- https://www.datacenterdynamics.com/en/opinions/is-your-cloud-network-ready-to-embrace-the-generative-ai-revolution/
- https://medium.com/@pdcloudx.digital/unlock-serverless-power-with-kubeless-knative-on-kubernetes-32949e9649bf
- https://srinimf.com/2021/07/05/5-layers-of-cloud-tricky-interview-question/
- https://www.osckorea.com/post/bigaebaljado-swibge-ihaehaneun-akitegceoyi-gaenyeom
- https://brunch.co.kr/@taehyo/7

최영대 컨설턴트
컨설팅사업부
5년 이상의 엔지니어 경험과 24년 이상의 경영 컨설턴트 경험을 기반으로 기업, 공공기관 등의 전략과 프로세스 혁신 관련 컨설팅을 수행합니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.