차세대 데이터 플랫폼 – 엘라스틱 스택(Elastic Stack)
엘라스틱서치(Elasticsearch)는 분산형 RESTful 검색 및 분석 엔진으로 엘라스틱 스택(Elastic Stack)의 중심에 위치한다. 엘라스틱 스택은 차세대 데이터 플랫폼이며 검색·분석·데이터 저장소 역할을 하는 엘라스틱서치, 데이터 수집을 담당하는 비츠(Beats), 정제·전처리를 수행하는 로그스태시(Logstash), 시각화·관리 기능을 제공하는 키바나(Kibana)로 구성된다.

엘라스틱은 매우 빠른 속도와 확장성, 복원성뿐 아니라 정형·비정형 데이터를 모두 수용할 수 있는 유연성을 가지고 있다. 이 같은 장점으로 인해 단순 검색엔진으로 활용하는 단계를 넘어 빠른 데이터 확인이 필요한 모든 분야에서 관심을 끌고 있다. 마케팅 분석·비즈니스 서비스·인프라 모니터링·보안-실시간 탐지 등이 대표적이다.
RDB(Relational Database)와 엘라스틱서치는 어떻게 다를까?
엘라스틱의 활용 사례가 늘어나면서 기존 DBMS를 엘라스틱으로 마이그레이션 하는 사례가 늘어나고 있다. 엘라스틱이 기존 DBMS 영역까지 넘볼 정도로 입지가 넓어지고 있긴 하지만 이를 완전히 대체할 수는 없다. 가장 큰 이유는 데이터 저장 방식 때문이다.
일반적으로 RDB는 행을 기반으로 데이터를 저장한다. 그에 반해 엘라스틱서치는 단어를 기반으로(역인덱스, Inverted Index) 데이터를 저장한다. 이로 인한 장단점은 분명하다.
RDB는 데이터 수정·삭제의 편의성과 속도 면에서 강점이 있지만 다양한 조건의 데이터를 검색하고 집계하는 데에는 구조적인 한계가 있다. 예를 들어 [그림 2]와 같이 도큐먼트를 행 기반으로 저장하고 ‘MSA’라는 단어를 검색해보자. 도큐먼트 개수만큼 ‘MSA’가 있는지 확인을 반복하기 때문에 많은 수의 도큐먼트가 있을 경우 비효율적일 수 밖에 없다.
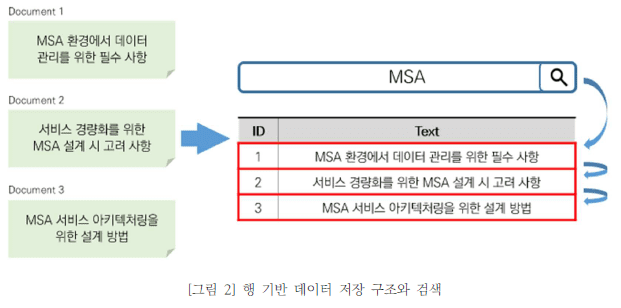
반면에 단어 기반으로 데이터를 저장하는 엘라스틱서치는 특정 단어가 어디에 저장되어 있는지 이미 알고 있어 모든 도큐먼트를 검색할 필요가 없다. 예를 들어 [그림 3]과 같이 역인덱스 구조로 저장한 상태에서 ‘MSA’라는 단어를 검색해보자. 행 기반 저장 구조와는 달리 단어가 저장된 도큐먼트를 알고 있기 때문에 도큐먼트 개수와 상관없이 한 번의 조회로 검색을 끝낼 수 있다.
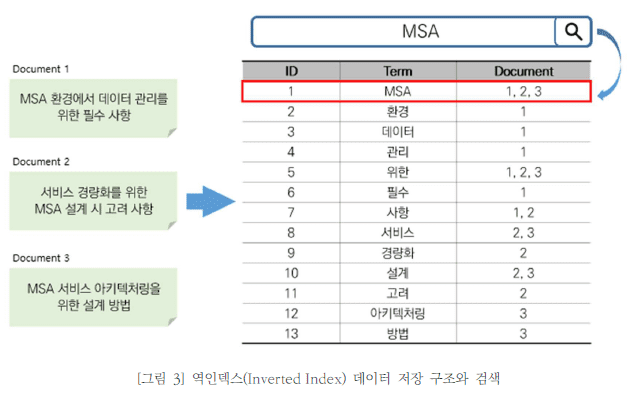
다만 수정과 삭제는 엘라스틱서치 내부적으로 굉장히 많은 리소스가 소요되는 작업이다. 이것이 엘라스틱서치가 RDBMS를 완전히 대체할 수 없는 중요한 이유 중 하나이다. 따라서 데이터 특성상 수정과 삭제가 많은 경우에는 RDB와 엘라스틱 영역을 나누어 아키텍처링 하는 것이 필요하다. 하지만 RDB와 공존하는 것이 매우 제한적인 상황에서 엘라스틱서치를 주로 사용해야 한다면 관계형 데이터 모델링을 고려해야 한다.
기존 DBMS와 엘러스틱서치의 데이터 모델링 방식에 대해 간단하게 살펴보자.
기존 DBMS를 RDBMS로 가정한다면 테이블 지향 데이터베이스(Table oriented Database)이기 때문에 일반적인 정규화(Normalization) 방법론을 기반으로 설계하면 된다. 반면 엘라스틱서치는 NoSQL 기반의 문서 지향 데이터베이스(Document oriented Database)로 같은 방법론을 적용하는 건 옳지 않다. 즉 엘라스틱서치에서는 기존에 알려진 방식으로 데이터 모델링을 할 수가 없다.
엘라스틱서치 데이터 모델링 방법론은 하나만 존재하진 않는다. 기존 DBMS와 달리 엘라스틱서치는 태생이 검색엔진이기 때문에 데이터의 유형, 검색 조건, 집계·시각화 여부 등에 따라 적절한 데이터 모델링을 적용해야 한다. 만약 이 같은 엘라스틱서치의 철학을 인지하지 못하고 데이터 모델링을 시작한 경우에는 이후 클러스터 설계부터 데이터 사이징, 쿼리 등 다양한 요소에서 문제점이 드러날 수 밖에 없다. 즉 엘라스틱서치를 제대로 사용할 수 없게 된다.
엘라스틱서치에서 관계형 데이터 모델링 방법은?
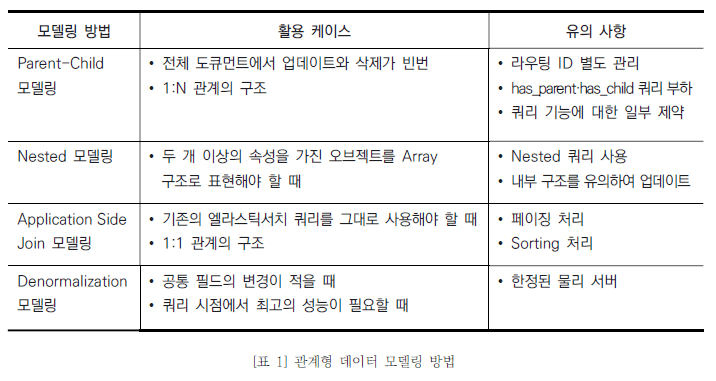
엘라스틱에서 관계형 데이터 모델링 방법은 크게 4가지가 있으며 각각 기술적 장단점이 분명하다. 때문에 자신의 데이터 특성 및 상황을 고려하여 적절한 모델링 방법을 활용해야 한다.
1) Parent-Child 모델링
엘라스틱서치가 제공하는 Join data type을 바탕으로 설계하는 방법이다. 하나의 인덱스에서 Parent와 Child 도큐먼트 간에 Join type으로 Parent, Child를 구분하고 Parent와 Child 도큐먼트에서 같은 라우팅 ID를 키로 제공하여 같은 샤드(Shard)에 위치하게끔 설계한다. 이 방식은 전체 도큐먼트에서 업데이트와 삭제가 빈번하고 1:N 관계의 구조일 때 고려해 볼 만하다. 유의 사항으로는 라우팅 ID를 별도로 관리해야 하는 점, 기존 쿼리에 비해 내부 연산이 많아 쿼리 자체에 부하가 있는 점(has_parent·has_child Query) 및 집계(Aggregation) 일부 쿼리 기능에 대한 제약 등이 있다.
2) Nested 모델링
엘라스틱서치에서 Nested data type을 활용해 설계하는 방법이다. 하나의 인덱스에서 Nested data type을 선언하고 오브젝트 속성들을 정의하여 연속(Array)하게 배치하는 방식이다. 두 개 이상의 속성을 가진 오브젝트를 배열(Array) 구조로 표현해야 할 때 고려해 볼 수 있다. 다만 이 방식을 사용할 경우 쿼리(Query)·집계(Aggregation) 및 업데이트(Update) 시 유의해야 한다. Nested Type은 내부적으로 Nested Object 별로 저장하기 때문에 Nested가 포함된 문서 하나를 저장할 때 실제 내부적으로는 Nested Array Size + 1만큼 저장하게 된다. 따라서 별도의 Nested Query를 작성해야 하고 업데이트 시 이러한 유의 사항을 고려해 디자인 해야 한다.
3) Application Side Join 모델링
기본 키(Primary Key)를 기준으로 관계(Relation) 있는 엔티티(Entity)들을 서로 다른 도큐먼트에 배치하여 Application side에서 키를 기준으로 조인(Join)하여 처리하는 방식이다. 이 모델링은 1:1 관계의 구조로 기존 쿼리와 집계(Aggregation)를 그대로 사용해야 할 때 고려해 볼 수 있다. 엘라스틱서치 쿼리를 그대로 사용 가능한 장점이 있으나 Application side에서 키 값을 기준으로 2회 이상 조회하여 가공해야 하므로 페이징 및 정렬(Sorting) 처리를 유의해야 한다. 일반적으로 관계가 있는 단순 조회 목적일 때 고려해 볼 만한 방법이다.
4) Denormalization 모델링
데이터 전체를 비정규화하여 인덱싱하는 방법으로 각 데이터의 중복을 허용하여 조인(Join)이 필요하지 않도록 한다. 이 기법은 조인(Join) 연산 자체가 필요 없으며 쿼리 시점에서 최고의 성능을 낼 수 있다는 점 때문에 잘 활용하면 최고의 모델링이 될 수 있다. 다만 데이터 크기가 기하급수적으로 증가할 수 있는 구조이기 때문에 공통 필드의 변경이 잦거나 한정된 물리 서버로 구성해야 한다면 유의해서 사용해야 한다.
Denormalization 모델링 시 엘라스틱에서 어떻게 데이터를 가공하고 처리해야 할까? 아래의 3가지 방법이 있다.
- Logstash JDBC Input 플러그인
Logstash Input 플러그인을 활용한 방법으로 JDBC 기반의 DBMS에서 직접 SQL 조인(Join)하여 비정형화된 데이터를 주기적으로 스케쥴링해 수집한다. 여러 테이블 간의 조인(Join) 처리를 RDBMS side에서 하기 때문에 복잡하고 주기적으로 수집이 필요한 경우 좋은 선택지가 될 수 있다.
- Logstash Translate Filter 플러그인
Logstash Filter 플러그인을 활용한 방법으로 바꾸려는 값들을 dictionary로 미리 정의하여 Input에서 데이터가 들어올 때 dictionary에 정의된 값이 있으면 해당 값으로 매핑하여 처리한다. 특정 데이터 값을 치환해야 할 때 유용하게 사용할 수 있다.
- Elasticsearch Ingest Pipeline Enrich 프로세서
엘라스틱 버전 7.5부터 사용할 수 있으며 Elasticsearch Ingest Pipeline에서 Enrich 프로세서를 활용하는 방법이다. Lookup 데이터를 엘라스틱서치에 미리 저장하고 Lookup의 조건을 Policy로 정의한다. 이 Policy에는 크게 Lookup 인덱스 명, match_field, enrich_field를 작성한다. 데이터 소스가 특정 Policy를 통해 들어올 경우 Policy 조건에 따라 Lookup된 데이터를 포함하여 인덱싱 한다.
엘라스틱서치에서 조인(Join)과 관련된 데이터를 유연하게 관리하고 유지할 필요성이 있는 경우 유용하게 사용할 수 있다. 유의할 점은 Policy 적용으로 생성된 enrich 데이터는 시스템 인덱스로 관리되고 인덱스를 자동으로 업데이트 하지 않기 때문에 Lookup 데이터 변경 시 별도의 업데이트 작업을 해주어야 한다.
마치며
엘라스틱서치에서 관계형 데이터 모델링 방법과 간단한 데이터 처리 방법까지 살펴보았다. 사실 실세계의 관계형 데이터들은 하나의 방법만으로는 해결하기 어려운 상황이 많다. 그렇기 때문에 다양한 방법을 조합하여 검증해야 한다. 아래 [표 1]은 앞서 설명한 모델링 방법을 요약한 것이다.
에스코어는 국내 최초의 엘라스틱서치 MSP(Managed Service Provider)로서 엘라스틱社가 공인한 엔지니어로 구성된 전문가 조직이 기술 조언, 문제 해결 및 케어팩(Carepack) 서비스를 원스톱으로 제공하고 있다.
# References
- https://www.elastic.co/kr/elastic-stack
- https://www.elastic.co/kr/blog/found-elasticsearch-as-nosql
- https://db-engines.com/en/article/Relational+DBMS?ref=RDBMS
- https://en.wikipedia.org/wiki/Inverted_index
- https://en.wikipedia.org/wiki/Database_normalization
- https://www.elastic.co/guide/en/elasticsearch/guide/current/relations.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/application-joins.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/denormalization.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/nested-objects.html
- https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html
- https://www.elastic.co/guide/en/logstash/current/plugins-filters-translate.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-enriching-data.html

안상희 프로
에스코어㈜ 소프트웨어사업부 컨버전스SW그룹
Elastic Stack 기술지원을 담당하고 있습니다. System architecting, Data sizing, Index design, Query design, Optimization 분야에 관심이 많습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.