클라우드 컴퓨팅의 대표적 장점으로 필요에 따라 서비스를 빠르게 확장하거나 축소할 수 있는 유연성을 들 수 있다. 오토스케일링(Auto Scaling)은 클라우드의 유연성을 돋보이게 하는 핵심 기술로 CPU, 메모리, 디스크, 네트웍 트래픽과 같은 시스템 자원들의 메트릭(Metric) 값을 모니터링 하여 서버 사이즈를 자동으로 조절한다. 이를 통해 사용자는 예상치 못한 서비스 부하에 효과적으로 대응하고 비용 절감 효과를 볼 수 있다.
클라우드 서비스를 이용하는 기업의 운영자는 벤더가 제공하는 자원 관리 기능을 활용해 자동 조절 정책(Auto-Scaling Policy)을 설정한다. 자동 조절 정책은 서버들의 묶음 단위인 오토스케일링 그룹(Auto-Scaling Group)에 연결되어 서비스가 유휴 상태일 때는 서버의 개수를 최소로 유지하고 부하가 발생하면 최대로 늘려 안정적이고 유연한 서비스를 구현한다.
오토스케일링 기능에 대한 이해를 돕기 위해 본 아티클에서는 AWS(Amazon Web Services)를 예로 들어 설명하겠다.
AWS의 오토스케일링 그룹에 설정되는 항목을 간략히 정리하면 다음과 같다.
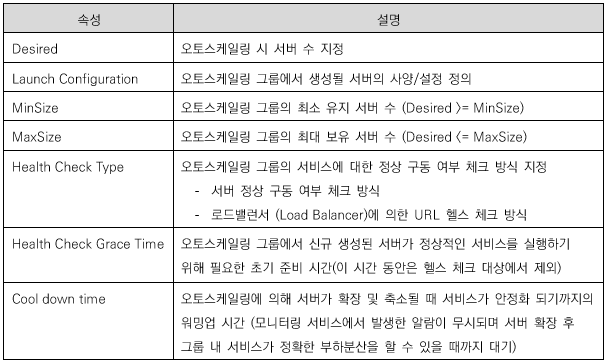
오토스케일링 발생 기준을 판단하기 위한 시스템 메트릭 지표
시스템 메트릭이란 가상 서버의 컴퓨팅 자원에 해당하는 CPU, 메모리, 네트웍과 같은 클라우드 리소스의 사용량 정보를 의미한다. 오토스케일링 그룹에 포함된 가상 서버의 시스템 메트릭 값이 지정된 임계치를 초과할 경우 가상 서버 수를 늘이고(Scale-out) 임계치 미만이면 가상 서버 수를 줄이도록(Scale-in) 설정할 수 있다.
AWS의 서버 인스턴스에 대한 모니터링 메트릭 지표는 다음과 같다.
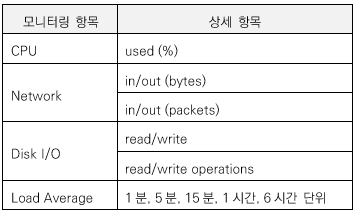
CPU는 사용률을 백분율로 가늠하고 네트웍은 입/출력 바이트 혹은 패킷으로 판단한다. 평균 부하 유지 기간은 1분, 5분, 15분 단위로 설정할 수 있다. 특이한 점은 디스크 성능 지표를 백분율 계측 방식이 아닌 디스크에 실제로 읽고(read) 쓴(write) 바이트 수와 디스크 액세스 오퍼레이션 회수로 측정해 정밀한 성능 판단 자료를 제공한다는 것이다.
서버 생성을 위한 시작 구성 템플릿(Launch Configuration Template)
AWS는 서버를 손쉽게 생성하기 위해 오토스케일링 그룹 내에 시작 구성(Launch Configuration) 템플릿을 제공한다. 운영 중인 서비스에 부하가 가해져 자동으로 서버 생성이 필요한 경우 시작 구성의 설정 내용에 따라 서버 인스턴스를 빠르게 만들어 장애를 방지할 수 있다.
시작 구성은 서버 OS 이미지 타입, 서버 스케일 사양 명세(CPU 코어 개수, 메모리 용량, OS 기본 스토리지 용량, 초기화 스크립트) 등을 정의한다. 이 구성은 한 번 생성하면 변경할 수 없고 삭제만 가능하다. 시작 구성이 제공하는 초기화 스크립트(Init Script)를 통해 초기 서버 설정값을 손쉽게 세팅 할 수 있다.(예: 비즈니스 서비스 로직을 위한 라이브러리 다운로드 및 서비스 네트워크 설정 등)
오토스케일링의 동작 원리
AWS가 제공하는 오토스케일링 기능의 동작 원리는 [그림 1]과 같다.
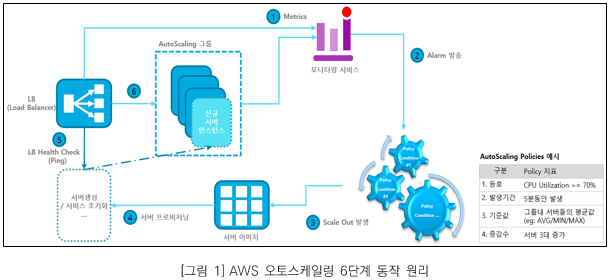
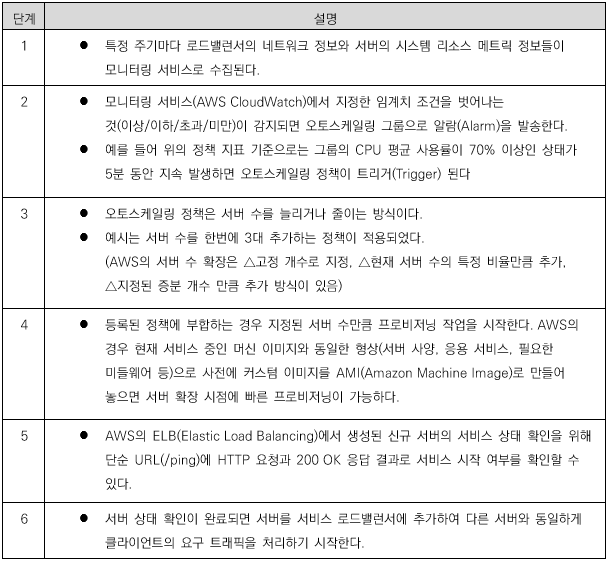
그림에서 파란색 원으로 표시된 단계마다 수행하는 기능은 다음과 같다.
오토스케일링은 △주기적으로 특정 시간대에 트래픽이 집중되는 서비스(혹은 서버 리소스가 적게 필요한 경우) △일괄 작업, 주기적 분석과 같은 워크로드 패턴 △특정 기간에 급증하는 트래픽 패턴 등 일 또는 주 단위로 트래픽 흐름이 변화하는 서비스에 유용하다.
이때까지 살펴본 바와 같이 클라우드 환경에서 오토스케일링 기술은 시시각각 변화하는 워크로드의 요구사항에 즉각 대응할 수 있어 비즈니스 특성에 부합하는 응용 솔루션을 효율적으로 운영할 수 있도록 한다. 시스템 리소스를 수분 내에 제어할 수 있고 응용 서비스 패턴에 맞추어 트래픽을 유연하게 배분하여 서비스 성능 및 가용성을 보장받을 수 있을 뿐 아니라 비용 절감 효과도 거둘 수 있다. 클라우드 서비스의 핵심 기술인 오토스케일링을 백분 활용하여 뛰어난 탄력성을 가진 인프라를 구현해보길 바란다.
# References
- https://docs.aws.amazon.com/autoscaling/ec2/userguide/what-is-amazon-ec2-auto-scaling.html
- https://docs.aws.amazon.com/autoscaling/ec2/userguide/AutoScalingGroup.html
손병창 프로
에스코어㈜ 소프트웨어사업부 엔터프라이즈플랫폼그룹
클라우드 아키텍처 및 플랫폼 개발을 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.