들어가며
Kubernetes는 컨테이너 기반 애플리케이션을 배포, 관리 및 스케일링하기 위한 오픈소스 플랫폼으로 다양한 환경에서 널리 사용되고 있다. 특히 클라우드 환경으로의 전환이 가속화되면서 Kubernetes의 활용도가 높아지고 있다. 클라우드 환경은 기존 온-프레미스 환경과 달리 네트워크 토폴로지가 복잡하고 동적인 특성을 가지고 있어, 이에 따른 네트워크 최적화가 필요하다.
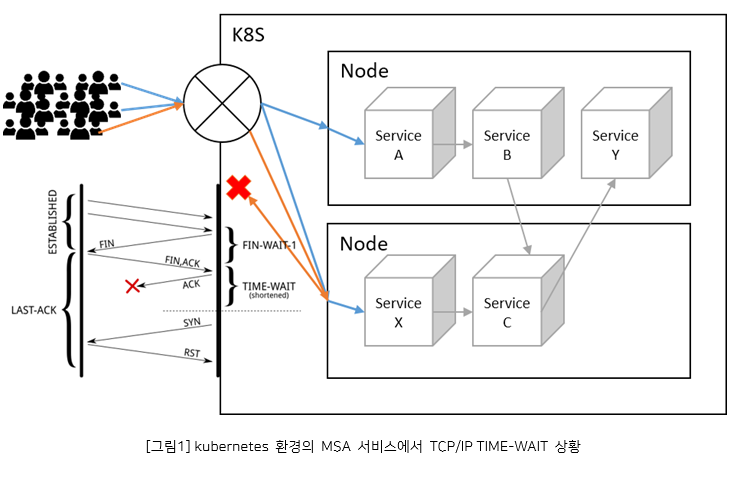
예로, 마이크로서비스 아키텍처(MSA)를 기반으로 한 전자상거래 플랫폼 애플리케이션에서 포트 고갈 문제가 발생했다고 가정해보자. 서비스 간 통신이 빈번해지면서 사용 가능한 포트가 모두 소진되어 새로운 연결 요청을 처리할 수 없는 상황이 되었다. 하지만 이 애플리케이션은 메모리 사용량이 비교적 낮은 수준이었고, 시스템 자원에 여유가 있었습니다. 따라서 TIME_WAIT 상태의 소켓을 재사용할 수 있는 커널 옵션인 net.ipv4.tcp_tw_reuse를 적용하기에 적합한 상황이었다. 이 옵션을 활성화하면 포트 고갈 문제를 해결하고 서비스 처리량을 높일 수 있을 것으로 예상된다. 메모리 사용량이 낮고 시스템 자원에 여유가 있어 소켓 재사용이 가능한 상황이었기 때문에, 이 옵션 적용을 통해 성능 개선을 기대할 수 있다.
또한, 대규모 프로모션 이벤트 기간 동안 짧은 시간에 과도한 트래픽이 몰린다고 가정해보겠다. 이때 요청 누락 문제가 발생할 수 있다. 이러한 상황에서 메모리 자원이 충분하다면 수신 버퍼 크기를 늘리는 커널 옵션인 net.core.rmem_max를 조정하는 것이 도움이 될 수 있다. 수신 버퍼 크기를 늘리면 더 많은 요청을 버퍼링할 수 있어 요청 누락을 방지할 수 있다.
이처럼 Kubernetes 환경에서 커널 네트워크 옵션을 적절히 활용하면 비즈니스 요구사항에 맞는 최적의 성능을 얻을 수 있다. 특히 클라우드 환경의 복잡한 네트워크 토폴로지로 인해 발생할 수 있는 문제를 해결하는 데 도움이 된다. 본 문서에서는 Kubernetes 환경에서 커널 네트워크 옵션을 활용하는 방법에 대해 자세히 소개하겠다.
컨테이너 기술과 OS 커널
Kubernetes에서 가장 기본이 되는 컨테이너 기술은 운영 체제의 커널과 네임스페이스(namespace) 개념을 활용하여 애플리케이션을 격리된 환경에서 실행할 수 있게 해준다. 커널은 운영 체제의 핵심 부분으로, 하드웨어 자원을 관리하고 프로세스 간의 자원 공유와 격리를 제어한다. 리눅스에서 네임스페이스는 커널 레벨에서 구현된 기술로, 프로세스 그룹이 서로 독립된 환경에서 실행될 수 있도록 시스템 리소스를 격리한다. 이 격리 기능은 컨테이너 기술의 핵심 구성 요소 중 하나로, 프로세스가 서로 간섭하지 않고 독립적으로 실행될 수 있게 한다.
컨테이너는 이러한 네임스페이스를 활용하여 호스트 운영 체제와 격리된 환경을 제공하며, 동일한 커널을 공유하면서도 프로세스, 네트워크, 파일 시스템 등의 리소스를 독립적으로 관리할 수 있다. 이를 통해 애플리케이션 배포 및 관리의 효율성과 보안성을 높일 수 있다. 예를 들어, containerd는 kubernetes를 구성할 때 널리 사용되는 컨테이너 런타임 엔진이다. containerd를 사용해 컨테이너 프로세스를 동작 중인 노드는 다음과 같은 구조로 동작한다.
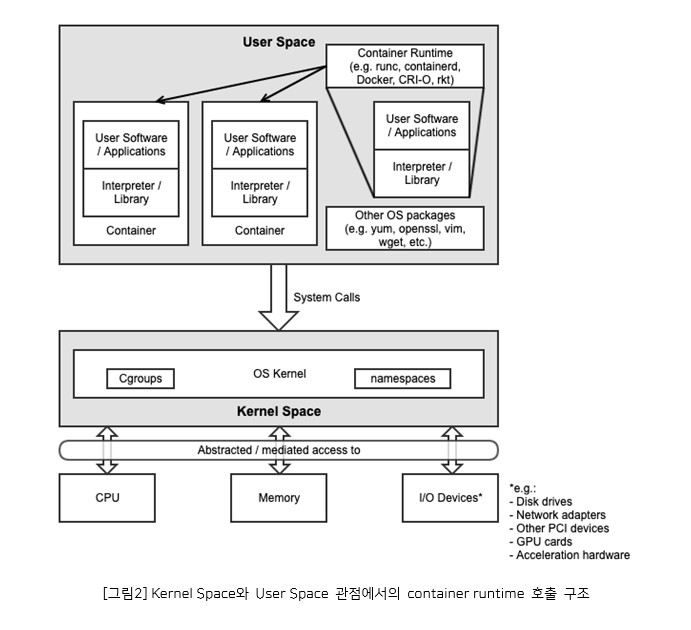
컨테이너는 결국 호스트 운영체제의 커널을 공유하며, 커널이 제공하는 기능과 자원 격리 메커니즘을 기반으로 동작한다. 커널은 컨테이너에 필수적인 네임스페이스, cgroups, 커널 기능과 같은 핵심 기술을 제공한다. 네임스페이스를 통해 프로세스, 네트워크, 마운트 등의 리소스가 격리되고, cgroups를 통해 CPU, 메모리, 디스크 I/O 등의 리소스 사용이 제한된다. 또한 커널의 기능들이 컨테이너의 보안과 효율성을 뒷받침한다. 따라서 커널은 컨테이너 기술의 근간이 되며, 컨테이너 런타임과 오케스트레이터는 커널이 제공하는 기능을 활용하여 컨테이너를 생성, 관리, 실행한다. 컨테이너 기술의 발전과 혁신은 커널 수준의 지원과 긴밀히 연관되어 있다.
커널 옵션 튜닝의 필요성
Kubernetes 클러스터의 성능과 효율성을 극대화하기 위해서는 커널 옵션을 최적화하는 것이 중요하다.
적절한 OS 커널 옵션 설정은 다음과 같은 이점을 제공한다.
* 성능 향상: 컨테이너 네트워킹 속도 향상, 메모리 사용량 최적화, 컨테이너 스케줄링 효율 개선 등을 통해 성능을 향상 시킬 수 있다.
* 비용 절감: 리소스 사용 효율성을 높여 클라우드 비용을 절감할 수 있다.
* 안정성 강화: 시스템 오류 및 컨테이너 실패 가능성을 줄여 안정성을 높일 수 있다.
따라서 제한된 자원으로 구성된 Kubernetes 환경에서 OS 커널 옵션 최적화를 통해 Kubernetes 클러스터의 성능, 효율성, 안정성을 크게 향상시킬 수 있다.
본 글에서는 Kubernetes 노드의 커널 옵션 튜닝 방안에 대해 자세히 다루겠다. 앞서, kubernetes의 기본이 되는 컨테이너 기술에 대해 설명했다. 컨테이너는 결국 호스트 노드의 커널 옵션에 영향을 받기 때문에 호스트 노드의 커널 옵션 설정이 중요하다. 네트워크 옵션은 컨테이너의 네트워크 성능에, 메모리 옵션은 컨테이너의 메모리 사용량과 효율성에 직접적인 영향을 주기 때문에 적절한 튜닝이 필요하다. 따라서 컨테이너 기술의 원리부터 실제 운영 환경에서의 활용까지 아우르며, 컨테이너 성능에 영향을 줄 수 있는 커널 네트워크 옵션, 메모리 관련 옵션들을 심도 있게 다루겠다.
kubernetes 노드의 커널 튜닝 방안
Kubernetes 클러스터는 일반적으로 여러 개의 노드로 구성된다. 각 노드는 컨테이너화된 애플리케이션을 실행하는 역할을 한다. 비즈니스 요구사항에 따라 클러스터의 노드 수가 제한되는 경우가 많다. 예를 들어, 비용 절감을 위해 노드 수를 최소화하거나, 하드웨어 리소스의 제약으로 인해 노드 수가 고정되는 경우가 있다. 이러한 상황에서는 각 노드의 성능을 최대한 활용하는 것이 중요하다. 노드 수가 제한되어 있기 때문에 개별 노드의 성능 최적화를 통해 전체 클러스터의 성능과 효율성을 높일 수 있으며, 노드 최적화를 위해서는 커널 수준의 설정 조정이 필요하다.
Kubernetes 노드는 기본적으로 Linux 운영 체제를 사용하므로 Linux 커널 옵션을 조정함으로써 노드의 성능을 개선할 수 있다. 특히, 네트워크와 메모리 관련 커널 옵션은 컨테이너 실행 환경에 직접적인 영향을 미치므로 중요하다. 본 문서에서는 Kubernetes 환경에서 운영체제의 커널 옵션 중 네트워크와 메모리 관련 옵션을 중점적으로 다루고자 한다. 이를 통해 제한된 노드 환경에서 최적의 성능을 발휘할 수 있는 방법을 소개하겠다.
kubernetes 구성 요소에 따른 커널 튜닝
* 네트워크 관련 커널 옵션
Kubernetes는 서비스 로드밸런싱, 클러스터 내부 통신, 인그레스 등 다양한 네트워킹 기능을 제공한다. 이러한 기능들은 커널의 네트워크 옵션에 의해 직접적인 영향을 받습니다. 예를 들어, TCP keepalive, TCP 재사용(tw_reuse), TCP 재전송 제어 등의 옵션을 조정하여 네트워크 성능과 안정성을 개선할 수 있다.
* 메모리 관련 커널 옵션
Kubernetes는 컨테이너의 메모리 할당과 제한을 관리한다. 이를 위해 커널의 메모리 관련 옵션을 적절히 설정해야 한다. 예를 들어, 메모리 스왑(swap) 비활성화, 메모리 과다 사용 방지를 위한 OOM(Out-of-Memory) 관리, 메모리 페이지 캐싱 등의 옵션을 조정할 수 있다. 또한, TCP 메모리 페이지, 읽기/쓰기 버퍼 용량, 동시 접속 제어 등의 옵션을 통해 메모리 사용 효율성을 높일 수 있다.
* 스케줄링 및 리소스 관련 커널 옵션
Kubernetes는 컨테이너를 노드에 스케줄링하고 리소스를 할당한다. 이 과정에서 커널의 CPU 관리, 프로세스 스케줄링, 파일 시스템 캐싱 등의 옵션이 관여한다. 예를 들어, CPU 할당 정책, 프로세스 우선순위 설정, 파일 시스템 캐싱 전략 등을 조정하여 리소스 활용도를 높일 수 있다.
네트워크 관련 커널 옵션
Pod에서 실행되는 애플리케이션의 네트워크 요구 사항과 클러스터 노드의 메모리 및 리소스 제약 조건을 고려해야 한다. 값을 너무 높게 설정하면 과도한 메모리 사용으로 인해 다른 Pod 또는 노드 구성 요소에 영향을 줄 수 있으며, 반대로 값을 너무 낮게 설정하면 네트워크 성능이 저하될 수 있다. 따라서 적절한 균형을 찾는 것이 중요하다.

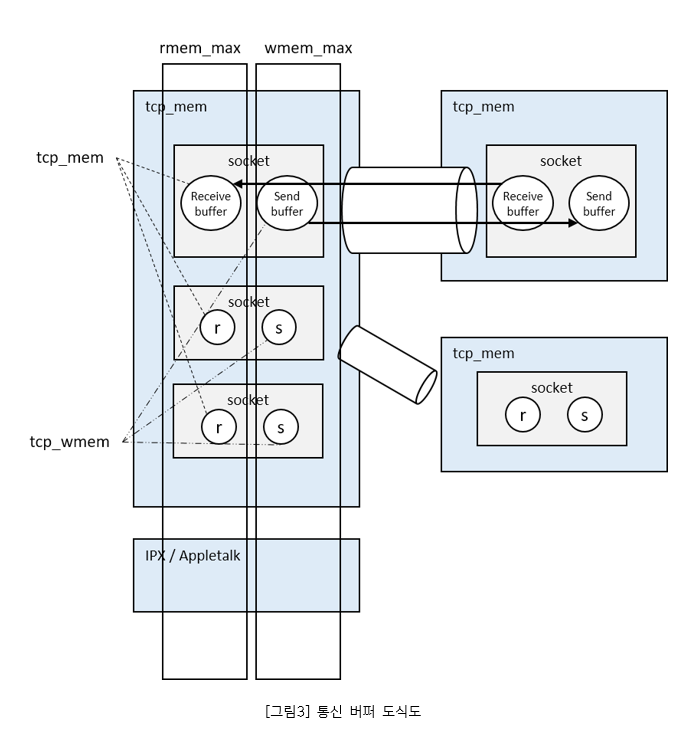
net.ipv4.tcp_mem: 이 옵션은 TCP 소켓 버퍼의 메모리 사용량을 제어한다. 값이 너무 낮으면 TCP 연결이 제한될 수 있고, 너무 높으면 과도한 메모리 사용으로 인해 다른 프로세스에 영향을 줄 수 있다. Pod에서 실행되는 애플리케이션이 많은 TCP 연결을 사용하는 경우 이 옵션을 적절히 조정하여 성능을 개선할 수 있다. 단위는 메모리 페이지이며 일반적으로 4k이며 세 가지 값은 TCP 메모리 사용량 수준(낮음, 중간, 높음)을 나타낸다. 262144 값은 1G 메모리(262144×4/1024/1024) 이다.
net.ipv4.tcp_wmem 및 net.ipv4.tcp_rmem: 이 옵션은 TCP 소켓 쓰기 및 읽기 버퍼의 크기를 제어한다. 값이 너무 낮으면 네트워크 성능이 저하될 수 있고, 너무 높으면 과도한 메모리 사용으로 인해 다른 프로세스에 영향을 줄 수 있다. Pod에서 실행되는 애플리케이션이 대량의 데이터를 송수신하는 경우 이 옵션을 적절히 조정하여 성능을 개선할 수 있다.
net.core.wmem_max 및 net.core.wmem_default: 이 옵션은 TCP 소켓 쓰기 버퍼의 최대 및 기본 크기를 제어한다. 값이 너무 낮으면 네트워크 성능이 저하될 수 있고, 너무 높으면 과도한 메모리 사용으로 인해 다른 프로세스에 영향을 줄 수 있다. Pod에서 실행되는 애플리케이션이 대량의 데이터를 전송하는 경우 이 옵션을 적절히 조정하여 성능 개선이 가능하다.
net.core.rmem_max 및 net.core.rmem_default: 이 옵션은 TCP 소켓 읽기 버퍼의 최대 및 기본 크기를 제어한다. 값이 너무 낮으면 네트워크 성능이 저하될 수 있고, 너무 높으면 과도한 메모리 사용으로 인해 다른 프로세스에 영향을 줄 수 있다. Pod에서 실행되는 애플리케이션이 대량의 데이터를 수신하는 경우 이 옵션을 적절히 조정하여 성능을 개선할 수 있다.
예를 들어 위의 기본 값은 131072=128k이다. 1M 파일은 8번만 전송할 수 있으므로 이미지 전송에 더 적합하다. 그러나 클수록 항상 좋은 것은 아니다. 예를 들어 텍스트 페이지가 15k에 불과한 경우 128k의 메모리를 사용하는 것은 비 효율적일 수 있다.

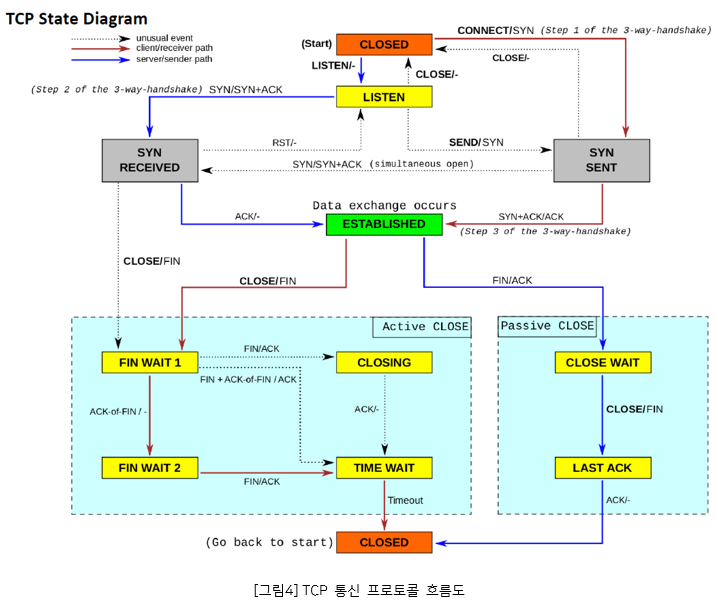
net.ipv4.tcp_tw_reuse: 이 옵션을 활성화하면 TIME_WAIT 상태의 소켓을 재사용할 수 있다. 이를 통해 포트 고갈 문제를 방지하고 더 많은 연결을 수용할 수 있다. 대량의 단기 연결이 필요한 애플리케이션에 유용하다. MSA 구조의 대규모 서비스에서는 하나의 서비스에서 요청을 처리하기 위해 다른 서비스에 질의하는 경우가 있다. 이 경우, 서버는 또 다른 서버의 클라이언트가 되므로 TIME_WAIT 상태의 소켓을 재사용할 필요가 있다.
net.ipv4.tcp_tw_recycle: 이 옵션을 활성화하면 TIME_WAIT 상태의 소켓을 즉시 재활용할 수 있다. TIME_WAIT 상태에 머무르는 시간을 변경하여 TIME_WAIT 상태의 소켓 수를 줄인다. 이는 tcp_tw_reuse보다 더 적극적인 방식이다. 단, 일부 환경에서는 문제를 일으킬 수 있으므로 주의해야 한다.
net.ipv4.tcp_timestamps: 이 옵션을 활성화하면 TCP 타임스탬프 옵션을 사용하여 더 나은 PAWS(Protection Against Wrapped Sequence Numbers) 기능을 제공한다. TCP timestamp가 사용되면 TIME_WAIT 상태의 소켓에 통신이 이루어진 마지막 시간(timestamp)를 기록할 수 있다. 이를 통해 TCP 연결의 안정성이 향상된다.
net.ipv4.tcp_fin_timeout: 이 옵션은 더 이상 애플리케이션에서 참조하지 않는 소켓(orphaned)이 FIN_WAIT_2 상태에 머무르는 시간(초)을 지정한다. 값이 작으면 포트가 더 빨리 재사용되지만 일부 연결이 중단될 수 있다.
net.ipv4.tcp_max_tw_buckets: 이 옵션은 시스템에서 동시에 보유할 수 있는 TIME_WAIT 버킷의 최대 수를 지정한다. 값이 클수록 더 많은 TIME_WAIT 소켓을 처리할 수 있지만 메모리 사용량이 증가하며, 이 숫자를 초과하면 시간 대기 소켓이 즉시 제거되며 경고가 발생한다. 기본값은 부팅 시 사용 가능한 메모리 양에서 계산된다.
net.ipv4.tcp_retries1 및 net.ipv4.tcp_retries2: 이 옵션은 TCP 연결 설정 중 재시도 횟수를 지정한다. 값이 작으면 연결 실패 가능성이 높아지지만 리소스 사용량이 줄어든다.
net.ipv4.tcp_keepalive_time, net.ipv4.tcp_keepalive_probes, net.ipv4.tcp_keepalive_intvl: 이 옵션은 TCP keepalive 동작을 제어한다. 값을 적절히 조정하면 비활성 연결을 더 빨리 감지하고 리소스를 절약할 수 있다.
net.ipv4.tcp_max_syn_backlog: 이 옵션은 수신 대기열의 최대 연결 수를 지정한다. 값이 작으면 연결 요청이 거부될 수 있다.
net.ipv4.tcp_max_orphans: 이 옵션은 할당된 메모리가 부족할 때 허용되는 최대 참조하지 않는(orphan) 소켓 수를 지정한다. 값이 작으면 메모리 사용량이 줄어들지만 연결 실패 가능성이 높아진다.

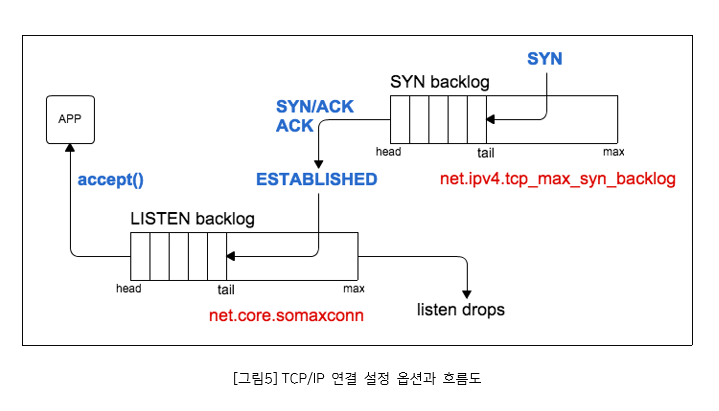
net.core.somaxconn: 최대 소켓 연결 수를 늘립니다. 이는 동시에 많은 연결을 처리해야 하는 네트워크 집약적인 애플리케이션(예: 웹서버)에 유용하다. 기본값 128에서 4096로 늘리면 Pod에서 실행되는 애플리케이션이 더 많은 동시 연결을 처리할 수 있다. 소켓 백로그 큐의 크기를 늘리면 메모리 사용량도 증가하나, 너무 높게 설정하면 메모리 부족으로 인해 시스템 성능이 저하될 수 있다.
net.core.netdev_max_backlog: 네트워크 인터페이스 수신 큐의 최대 크기를 설정한다. 각 네트워크 별로 커널이 처리하도록 쌓아두는 큐의 크기이다. 이 값을 늘리면 버퍼 오버플로우 발생 가능성이 줄어든다. 네트워크 트래픽이 많은 Pod에 도움이 될 수 있다.
net.ipv4.ip_local_port_range: 로컬 포트 범위를 설정한다. 이 범위에서 임시 포트가 할당되며, 많은 수의 동시 연결이 필요한 경우 이 범위를 넓히면 도움이 된다.
net.netfilter.nf_conntrack_max 및 net.nf_conntrack_max: 연결 추적 테이블의 최대 크기를 설정한다. 이 값을 늘리면 더 많은 연결을 추적할 수 있다.
nf_conntrack_max 값은 CPU에 따라 달라지며, CPU가 8개인 서버는 최소값인 655350보다 낮은 8 x 65535 = 524280의 conntrack_max를 갖게 되므로 nf_conntrack_max를 655350으로 설정해야 한다. CPU가 32개인 서버는 32 x 65535 = 2097129로 최소값인 655350보다 크므로 nf_conntrack_max를 2097120으로 설정한다.
net.ipv6.conf.all.disable_ipv6: IPv6를 비활성화한다. IPv6를 사용하지 않는 경우 이 설정으로 약간의 성능 향상을 기대할 수 있다.
net.netfilter.nf_conntrack_tcp_timeout_established: 설정된 시간(초) 동안 비활성 상태인 TCP 연결을 유지한다. 장기 실행 연결이 필요한 경우 이 값을 늘려야 할 수 있다.
메모리 관련 커널 옵션

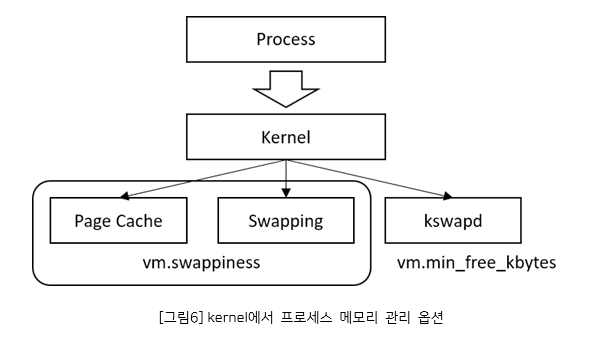
vm.dirty_ratio: 커널이 수정된(“더티”) 메모리 페이지를 디스크에 다시 쓰기로 선택하는 시기를 결정한다. 이 옵션은 커널이 디스크에 데이터를 쓰기 전에 메모리에 유지할 수 있는 더티 페이지의 최대 비율을 제어한다. 값이 높을수록 커널은 더 많은 데이터를 메모리에 캐싱할 수 있으므로 쓰기 성능이 향상된다. 그러나 메모리 사용량이 증가하므로 메모리 부족 상황에 주의해야 한다. “더티 페이지(dirty page)”란 메모리 상에 존재하는 데이터로, 이미 디스크에 기록된 내용이지만 아직 디스크와 메모리 간의 일관성을 유지하기 위해 디스크로 쓰여지지 않은 데이터를 말한다.
vm.min_free_kbytes: 이 옵션은 커널이 유지해야 하는 최소 여유 메모리 양을 지정한다. 값이 클수록 커널은 더 많은 메모리를 여유 공간으로 확보하므로 메모리 부족 상황을 방지할 수 있다. 그러나 애플리케이션에 사용 가능한 메모리가 줄어들 수 있고, 너무 높게 설정하면 시스템이 즉시 OOM을 낼 수 있다. 반면에 너무 낮은 값을 설정하면 부하가 높을 때 교착 상태가 발생하기 쉽고, 운영체제의 핵심 서비스에서 장애가 발생할 수 있다.
vm.vfs_cache_pressure: 이 옵션은 커널이 페이지 캐시를 재활용하는 빈도를 제어한다. 값이 높을수록 커널은 더 적극적으로 페이지 캐시를 재활용하여 메모리를 확보한다. 이는 메모리 부족 상황에서 유용하지만, 디스크 I/O 성능이 저하될 수 있다. 기본값인 100으로 설정하면 커널은 페이지 캐시 및 스왑 캐시 회수와 관련하여 “공정한” 비율로 dentries와 inode를 회수하려고 시도한다. 반면 값이 0인 경우 커널은 메모리 압박으로 인해 dentries와 inode를 회수하지 않으며, 이로 인해 메모리 부족 상태가 쉽게 발생할 수 있다.
만약 vfs_cache_pressure를 100 이상으로 크게 늘리면 성능에 부정적인 영향을 미칠 수 있다. vfs_cache_pressure=1000을 사용하면 해제 가능한 오브젝트를 기존보다 10배 더 많이 찾게 된다. 페이지 캐시를 재활용할 필요가 없는 애플리케이션의 경우 유용할 수 있다. GlusterFS와 같은 스토리지 클러스터링 애플리케이션에서는 필요에 따라 높은 값을 할당하는 것을 제안하고 있다.
위와 같은 옵션을 조정하면 Pod에서 실행되는 애플리케이션의 메모리 및 디스크 I/O 성능에 영향을 미칠 수 있다. 예를 들어, 메모리 집약적인 애플리케이션의 경우 vm.swappiness를 낮추고 vm.min_free_kbytes를 높이면 OOM killer 발생 가능성을 줄일 수 있다. 반면에 디스크 I/O 집약적인 애플리케이션의 경우 vm.dirty_ratio를 높이고 vm.vfs_cache_pressure를 낮추면 쓰기 성능을 향상시킬 수 있다.
그러나 이러한 옵션을 무작정 조정하면 부작용이 발생할 수 있으므로 주의해야 한다. 애플리케이션의 요구 사항과 클러스터 노드의 리소스 제약 조건을 고려하여 적절한 값을 설정해야 한다. 또한, 모니터링 도구를 사용하여 옵션 변경 후 애플리케이션 성능과 리소스 사용량을 면밀히 관찰해야 한다.
마치며
Kubernetes 환경에서 커널 네트워크 옵션을 적절히 활용하는 것은 비용 효율성을 높이는 중요한 전략이다. 네트워크 성능을 최적화함으로써 리소스 사용률을 개선하고, 전체 시스템의 처리량을 증가시킬 수 있다. 이는 클라우드 환경에서의 비용 절감으로 직결될 수 있으며, 사용자 경험을 향상시키는 데에도 기여한다. 커널 옵션을 통한 세밀한 튜닝은 불필요한 네트워크 지연을 줄이고, 데이터 처리 속도를 향상시켜, 최종적으로는 비즈니스 요구에 더욱 민첩하게 대응할 수 있는 시스템을 구축할 수 있다.
Kubernetes를 효과적으로 활용하기 위해서는 단순히 애플리케이션을 배포하고 운영하는 것을 넘어서, 시스템 전반의 성능을 이해하고 최적화하는 노력이 필요하다. 커널 네트워크 옵션 튜닝은 그 중 하나의 방법으로, 클러스터의 안정성과 성능을 동시에 증진시킬 수 있다. 또한, 지속적인 모니터링과 분석을 통해 시스템의 변화에 신속하게 대응하고, 필요에 따라 커널 설정을 조정하여 시스템을 최적의 상태로 유지하는 것이 중요하다.
Kubernetes 클러스터의 관리와 운영에 있어 커널 옵션의 조정은 기술적 도전이 될 수 있지만, 이를 통해 얻을 수 있는 이점은 매우 크다. 따라서, Kubernetes를 사용하는 조직에서는 이러한 고급 설정에 대한 지식과 경험을 갖춘 인력을 확보하거나 교육해야 한다.
# References
- time_await: https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux
- somaxconn: https://kenzo0107.github.io/2021/04/15/2021-04-16-nginx-on-fargate-somaxconn/
- kernel_net: https://www.kernel.org/doc/Documentation/sysctl/net.txt
- kernel_ip: https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
- kernel_vm: https://www.kernel.org/doc/Documentation/sysctl/vm.txt
- kernel_sysctl: https://www.kernel.org/doc/Documentation/networking/nf_conntrack-sysctl.txt
- kernel_scaling: https://www.kernel.org/doc/Documentation/networking/scaling.txt
- kernel_vm: https://www.kernel.org/doc/Documentation/sysctl/vm.txt
- kernel_FAQ: https://www.kernel.org/doc/Documentation/networking/netdev-FAQ.txt
- container protocol stack: https://www.openeuler.org/en/blog/MrRlu/2020-12-04-cloud-native-network-dp-analysis.html
- containerd architecture: https://www.alibabacloud.com/blog/getting-started-with-kubernetes-%7C-further-analysis-of-linux-containers_596290
- linux network kernel parameter: https://meetup.nhncloud.com/posts/55
- azure aks kernel options: https://learn.microsoft.com/ko-kr/azure/aks/custom-node-configuration?tabs=linux-node-pools
- glusterfs linux kernel tuning: https://docs.gluster.org/en/main/Administrator-Guide/Linux-Kernel-Tuning/
- linux net.core.somaxconn: net.core.somaxconn
- kubernetes sysctl cluster: https://kubernetes.io/ko/docs/tasks/administer-cluster/sysctl-cluster/

이현승 프로
소프트웨어사업부 OSS사업팀
클라우드 및 오픈소스 SW 관련 연구 개발 프로젝트를 수행하였으며, 현재 OSS 기술서비스 및 아키텍처를 담당하고 있습니다.
-
다음 글



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.