들어가며
오늘 날 인터넷은 다양한 분야에서 여러가지 용도로 활용되고 있지만, 가장 근본적이고 일반적인 용도는 웹에서 다른 이들에게 정보를 공유하는 것이다. 이를 위해 가장 흔하게 인터넷을 활용하는 방식은 다른 사람들이 볼 수 있도록 웹페이지를 만들거나 게시글을 작성하거나, 또는 작성한 내용을 다른 이들에게 이메일로 발신하는 것이다.
웹 페이지나 웹에서 작성된 문서는 일반적으로 HTML(HyperText Markup Language) 형식의 데이터로 표현되며 HTML 데이터가 자주 활용되는 만큼 이와 관련 내용이 잘 알려져 있지만, 웹 문서 및 웹에서 작성된 내용이 이메일로 전송될 때 어떤 형식을 갖는지는 많이 알려져 있지 않다.
이 글에서는 이메일 데이터의 형식적인 구조를 이루는 MIME / MHTML형식에 대해 예시와 함께 간략하게 소개한 뒤, HTML을 MHTML 변환하는 흐름을 살펴보고자 한다.
이메일과 관련된 형식 종류와 고려 사항
이메일과 관련된 형식에 관해 알아야 할 부분은 크게 3가지이다.
- IMF (Internet Message Format)
- MIME (Multipurpose Internet Mail Extensions)
- MHTML (MIME Encapsulation of Aggregate Documents, such as HTML)
여기서 IMF는 이메일 전체 형식에 대한 표준이며 MIME / MHTML의 경우 이메일의 내용을 구성하는 형식에 대한 표준이다. 각 항목별로 내용을 조금 더 살펴보자.
IMF (Internet Message Format)
아래 내용은 IMF 에 따라 간단하게 작성된 이메일 본문 데이터 예시이다.

IMF는 이메일을 통하여 ‘텍스트 메시지’를 교환할 때, 해당 메시지의 문법을 규정하는 표준이다. 해당 표준에는 메시지 전송을 위해 필요한 정보를 포함하는 부분(‘envelope’)과 수신자에게 전달하고자 하는 내용에 대한 부분(‘contents’)를 규정하고 있다. 위의 예시에서 쉽게 확인 가능한데, ‘From’부터 ‘Message-ID’는 이메일이 오고 가는데 필요한 정보인 ‘envelope’에 해당하는 부분이며 개행을 통해 분리되어 있는 ‘This is test.’이 실제 이메일 내용인 ‘contents’에 해당한다.
메일이 올바르게 수신자에게 전달되기 위해 필요한 정보를 IMF 표준에 따라 작성하기 때문에 이메일 송/수신에 있어서 중요하며, 이메일을 다루는 에이전트나 어플리케이션은 해당 표준을 따르고 있다. 하지만 IMF는 ‘텍스트 메시지’ 교환에 대해서만 정의하기 때문에 HTML을 비롯하여, 멀티미디어나 파일 등 일반 텍스트가 아닌 다양한 컨텐츠로 구성된 이메일의 송/수신 형식을 정의하기 위해서는 별도의 표준이 필요하다. 이에 더해, IMF에서는 메시지 내용을 일련의 US-ASCII 문자의 나열로 정의하고 있기 때문에 오늘날 유니코드로 표현되는 다국어나 자주 사용되는 이모지 역시 해당 표준만으로는 이메일에서 표현이 불가하다.
이와 같은 한계점을 보완을 위해 이메일 본문 부분을 확장하는 표준인 MIME 및 MHTML이 필요하다.
MIME (Multipurpose Internet Mail Extensions)
MIME은 IMF의 한계를 넘어 일반 텍스트뿐만 아니라 HTML 데이터, 멀티미디어 등 다양한 형식을 메일 데이터에 포함할 수 있도록 하는 표준이다. MIME 형식으로 작성된 데이터는 일반 텍스트로만 정의된 IMF의 ‘contents’ 부분을 대체하게 된다.
단, 여전히 IMF 표준은 US-ASCII만을 지원하기 때문에 MIME 형식 데이터가 이메일로 정상적으로 전달될 수 있도록, IMF 표준에 맞게 ‘contents’ 부분을 대체하기 위해서는 MIME 형식 데이터 역시 US-ASCII 문자 범위로 해당 데이터가 인코딩 되어야 한다.
아래는 웹 에디터에 작성된 본문을 MIME 형식으로 변환한 내용이다.

위 데이터를 통해 개략적인 MIME의 구조와 포함 내용을 알 수 있는데, 첫 줄의 ‘MIME-Version부터 4번째 줄의 Content-Transfer-Encoding: base64’ 까지가 Header 영역에 해당하며, 빈 줄로 분리된 그 아래의 Base64 인코딩된 데이터가 Body에 해당한다.
가장 상단에 작성된 ‘MIME-Version: 1.0’의 경우 US-ASCII와 다른 인코딩을 사용하는 시스템에서 이메일 메시지를 위한 US-ASCII 인코딩과의 호환을 보장할 때, MIME의 Header에 해당 내용을 추가한다.
‘Content-Type’은 해당 MIME이 어떤 형식인지 알려주는 필드이며 뒤이어 작성된 미디어 타입을 통해 실제로 어떤 종류의 데이터인지 나타내게 된다. 위 예시에서, text/html이 미디어 타입에 해당하며, 우리가 흔히 MIME type이라고 부르는 형식이기도 하다. 이때 ‘/’를 기준으로 앞은 ‘type’, 뒤를 ‘subtype’이라 지칭하며 해당 예시에서는 ‘text’가 ‘type’, ‘html’이 ‘subtype’이 된다.
한편, charset=”utf-8”은 parameter에 해당하는데, 미디어 타입의 종류에 따라 parameter가 추가되기도 하며 생략되기도 한다. charset은 ‘type’이 text일때 추가되며, 현재 예시로는, 본래의 HTML 문자열 데이터가 utf-8로 인코딩 되었다는 것을 의미한다.
Content-Transfer-Encoding은 현재 MIME의 Body가 어떤 형식으로 인코딩 되어 있는지를 나타내며, 위 내용을 통해 base64 형식으로 인코딩 되어 있음을 알 수 있다.
인코딩 값에는 주로 US-ASCII 문자 범위(7bit)에서 표현되는 인코딩이 사용되지만, binary나 8bit 인코딩이 사용되기도 한다.
줄 바꿈을 통해 분리되어 있는 문자열은 Body영역으로 MIME의 실제 데이터에 해당한다. 위 예제에서의 Body는 앞서 설명한 Header의 필드 값에 따라 base64로 인코딩 된 HTML 문자열 데이터라는 것을 알 수 있다.
한가지 더 예제를 살펴보자면,
아래는 웹 에디터 본문에 포함된 png 이미지를 MIME 형식으로 변환한 내용이다.

원본 데이터의 타입과 맞도록 ‘Content-Type’ 필드 값이 ‘image/png’ 로 작성되었으며, 미디어 타입의 type이 text가 아닌 image이기 때문에 parameter가 생략되었다.
한편 이전 예제에는 없던 ‘Content-ID’ 필드가 추가되었는데 이는 참조되는 데이터를 표현하는 MIME 쪽에 추가되는 필드로, 해당 데이터를 참조할 때, 해당 데이터를 다른 데이터와 구분해서 식별할 수 있도록 유일한 값을 필드 값으로 설정해주어야 한다.
MIME 데이터의 문자열 구조에도 신경 써야 한다. Body영역의 각 인코딩 방식에 따른 문자열 처리와 MIME 표준에 작성된 각 필드 별 허용 문자를 확인하여 작성할 필요가 있으며 Header 영역과 Body영역은 개행을 통해 구분 지어야 한다.
(예제에서 보이는 base64 인코딩의 경우 한 줄에 76자가 되어야 하며, 인코딩 후 필요시 ‘=’를 통한 padding이 추가될 수 있다.)
MHTML (MIME Encapsulation of Aggregate Documents, such as HTML)
HTML 문법에서는 웹페이지 렌더링에 필요한 리소스를 각 <tag>에서 여러가지 방법으로 참조할 수 있다. 이러한 HTML의 구조적인 특징을 참고하여 HTML과 유사하게 하나의 MIME이 다른 리소스에 해당하는 MIME을 참조하도록 구조를 구성한 것을 MHTML이라고 한다.
이를 위해 여러 개의 MIME이 합쳐진 형태로 MIME을 작성하게 되는데, 이때 포함되는 각각의 MIME형태 데이터들을 Entity라 한다. MHTML로 데이터를 정의하게 되면 여러 개의 데이터가 포함되었다는 것을 나타내기 위해 Content-Type이 ‘multipart’인 Entity를 정의하게 된다. 일반적으로 root에 해당하는 Entity의 실제 데이터에서 메일에 포함되어야 하는 리소스를 URI로 참조하게 되므로, 리소스에 해당하는 각 Entity는 각각 참조할 수 있는 URI를 제공하게 된다.
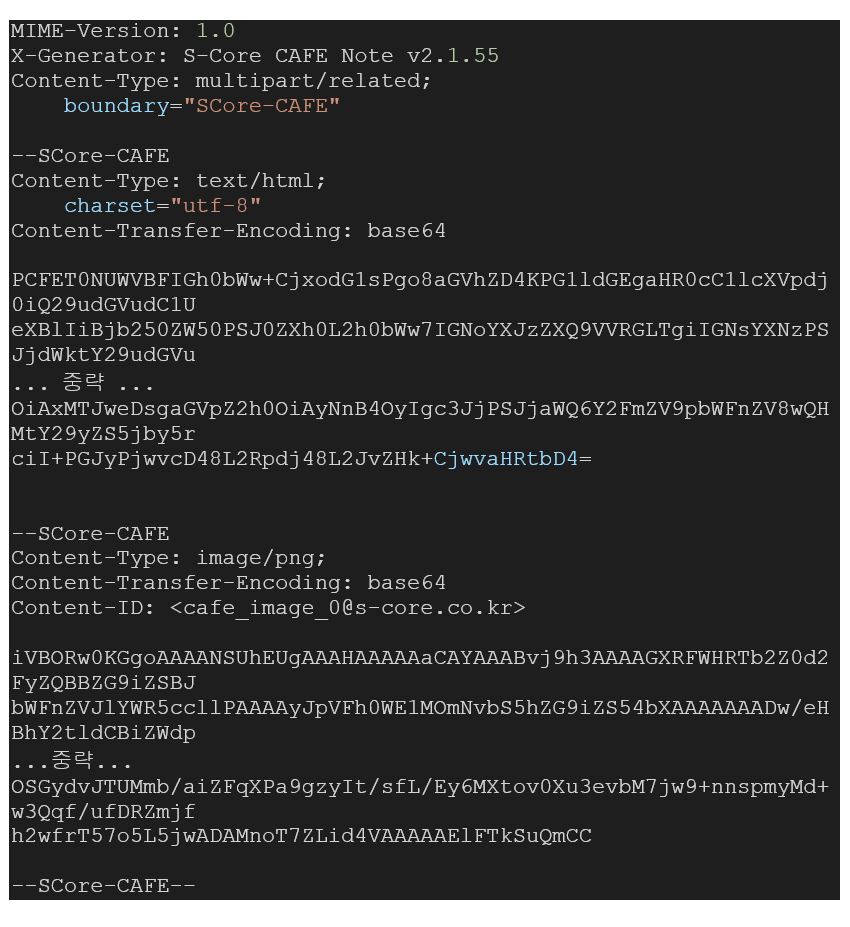
아래는 HTML에 base64로 인코딩 된 이미지가 삽입되어 있는 데이터를 MHTML로 변환 한 내용이다.
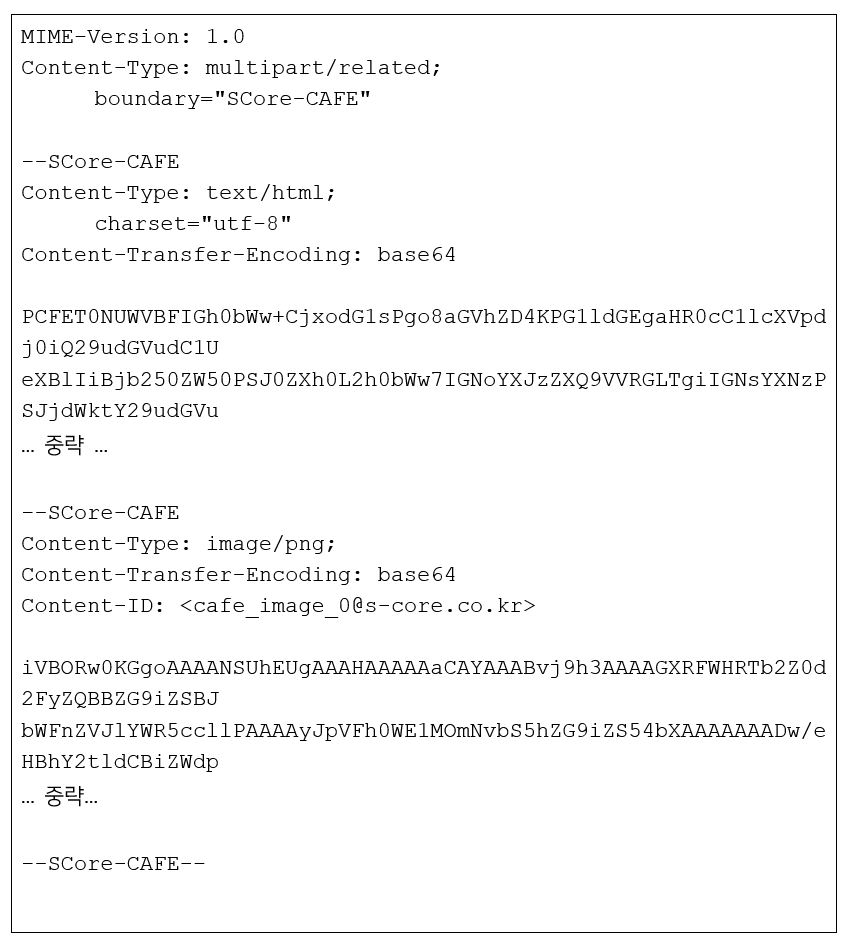
MIME의 최상단에 위치한 Entity를 보면 별도의 Body 영역이 없으며, 앞에서 언급했던 대로 Content-Type의 필드 값이 ‘multipart/related’인 점을 확인 할 수 있다. 즉 해당 MIME 내에 HTML 본문과 이미지를 함께 포함하도록 하겠다는 의미이다.
Content-Type에 boundary라는 parameter가 함께 추가되었는데, 이는 Content-Type이 ‘multipart’일 때 추가되며, 두개의 하이픈(–)과 결합하여 각각의 Entity을 구분하는 용도로 사용된다. 위 예제에서 각각의 Entity가 –SCore-CAFÉ를 통해 구분되고 있는 것을 확인할 수 있다.
이미지 데이터에 해당하는 Entity에는 ‘Content-ID’가 정의되어 있으며 해당 값을 통해 root에 해당하는 Entity에서 이 이미지를 참조할 수 있다. base64로 인코딩 되어 있는 HTML 본문 데이터의 이미지 삽입부분인 <img> 태그의 ‘src’ 속성에는 CID로 ‘Content-ID’의 값을 URI형식으로 참조한다. (src=’cid:cafe_image_0@s-core.co.kr’)
앞서 설명한 예제는 헤더의 ‘Content-ID’ 필드를 활용하지만 아래와 같이 헤더의 ‘Content-Location’ 필드를 활용하여 해당 리소스의 URI를 정의해주기도 한다.
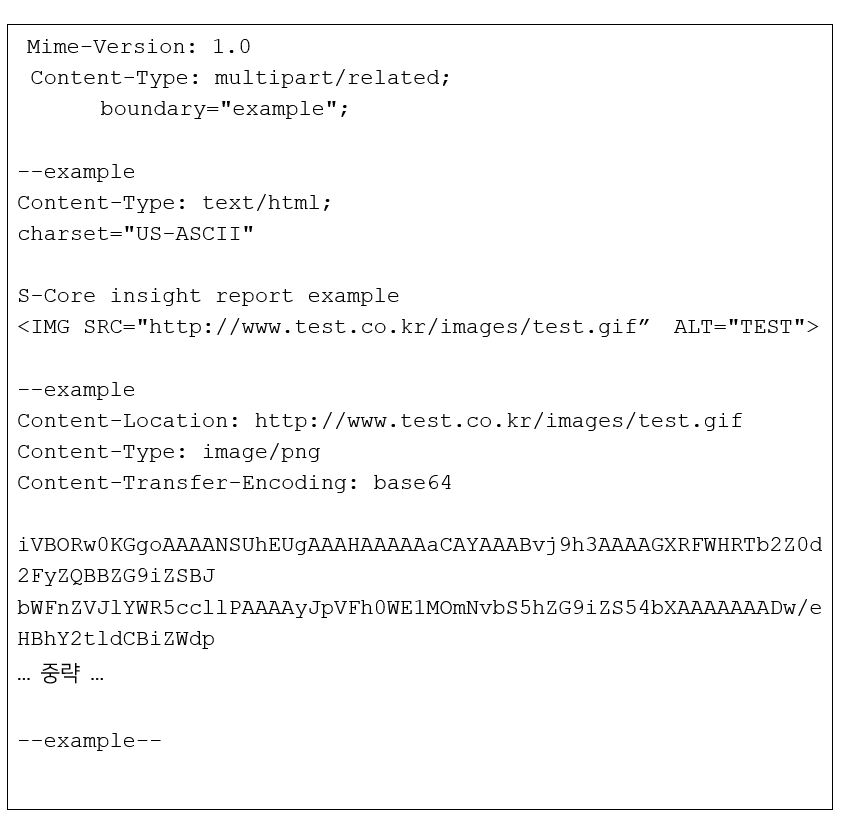
다만 Content-Location에 정의된 URI가 수신자가 접근 불가능한 URI라면 수신자가 해당 Entity의 데이터에 접근 불가능할 수 있다.
추가로 위와 같이 Content-Type의 type이 ‘multipart’인 경우, ‘Mime-Version: 1.0’은 한번만 기술하게 된다.
앞선 예제와 설명과 같이 MHTML 자체는 이메일을 위한 메시지 형식 전체를 나타내는 것은 아니며, 메시지 내용(‘contents’ 부분)을 다양한 형식의 데이터로 구성하기 위해 사용된다.
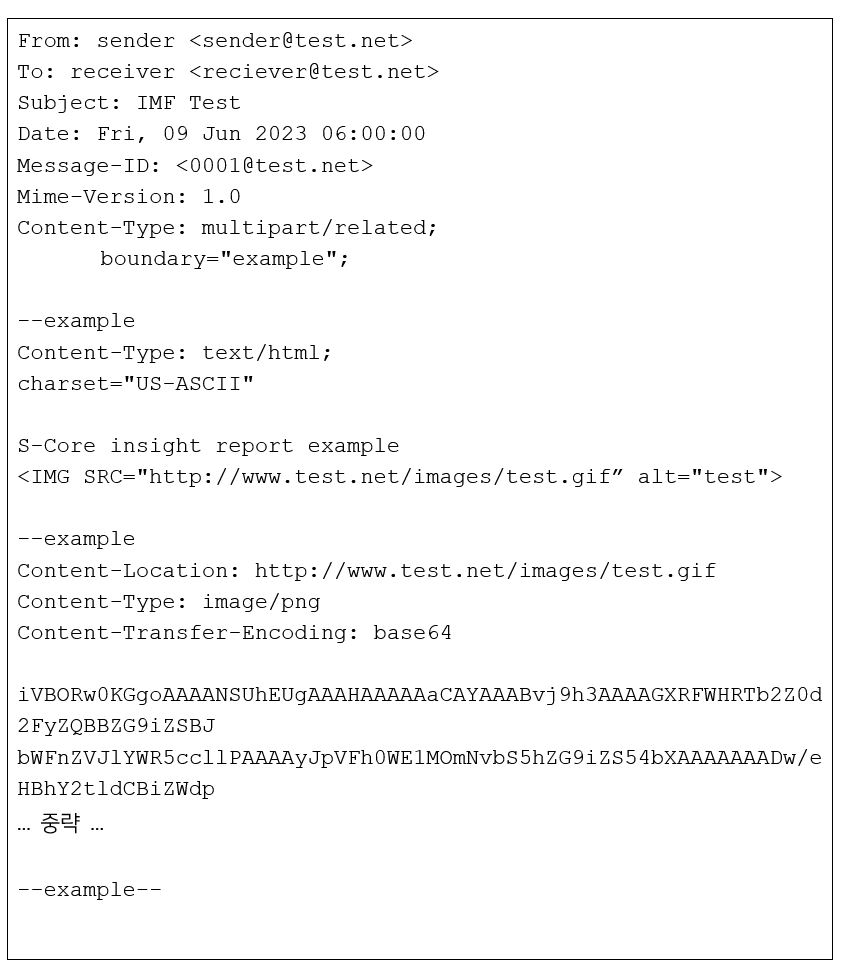
앞서 보았던 IMF 형식에 맞게 contents 내용을 MHTML 형식 데이터로 대체하면 아래와 같은 형태의 이메일 메시지가 된다. 일반적으로 .eml 확장자가 붙는 파일이 이와 유사한 형태로 구성된다.
이메일과 관련된 형식 종류와 고려 사항
앞서 설명한 내용을 활용하여 웹 에디터 등에서 직접 작성한 HTML 형식의 본문이나 웹페이지의 HTML 데이터를 MHTML로 변환할 수 있다.
변환은 간단하게 말하면, 1) HTML의 MHTML 변환 범위 결정, 2) 리소스 참조 여부 확인, 3) 각 MIME 또는 Entity의 Header 구성, 4) HTML 본문 데이터 및 리소스 데이터 인코딩, 5) MIME Header와 Body 합치기의 순서로 진행된다.
각 항목에 대해 조금 더 자세히 살펴보자
(해당 내용은 Front-End에서 JavaScript를 통해 변환하는 것을 전제로 하고 있다.)
1) HTML의 MHTML 변환 범위 결정
웹 페이지 중 어떤 부분을 MHTML로 변환할지 판단이 필요하다. 웹 페이지 전체에 해당하는 HTML을 MHTML로 변환할 수도 있고 특정 부분만 MHTML로 변환할 수도 있다. 예를 들어 웹 페이지에 삽입되어 있는 에디터에서 작성된 내용을 변환하고자 한다면, 해당 에디터의 작성창 영역에 해당하는 HTML을 대상으로 MHTML 변환을 고려해야 한다.
2) 리소스 참조 여부 확인
만약 변환하고자 하는 HTML 데이터에서 다른 리소스를 전혀 참조하지 않는다면 MHTML 형식에서 설명했던 대로 Content-Type이 text/html인 MIME으로 변환하면 되는 반면, 리소스를 참조하고 있다면 Content-Type이 multipart/related 가 되도록 변환이 되어야 하며 각 리소스를 multipart의 각 Entity로 변환해야 하기 때문에 리소스 참조여부에 대한 확인이 필요하다.
※ HTML에서 이미지를 참조하는 예: <img src=”data:image/png;base64,iVBO…하략…”>
이를 위해 정규표현식이나 문자열 처리를 통해 문자열 상태의 HTML에서 리소스 참조여부를 확인할 수도 있고, MHTML을 변환하고자 하는 영역의 DOM Tree를 순회하면서 확인할 수도 있다. 다만 HTML 문자열에서 이를 처리할 경우, 리소스 참조를 위한 코드 영역과 사용자가 편집창에 직접 작성한 URI를 구분하기 어려울 수 있다.
※ HTML 문자열을 얻는 예: body.outerHTML;
※ DOM Tree에서 이미지 리소스를 찾는 예: body.querySelectorAll( “img[src]” );
3) 각 MIME 또는 Entity의 Header 구성
공통적으로 Mime-Version: 1.0 이 추가되어야 하며, 리소스 참조여부에 따라 각 상태에 맞게 Header 문자열을 구성한다.
HTML 데이터에서 리소스를 참조하지 않는다면 MIME의 첫번째 예제와 같은 형태로 Header 문자열을 구성해야 한다.
이때 Content-Transfer-Encoding 필드에 작성된 인코딩 형식과 Content-Type의 charset parameter에 작성된 인코딩 형식을 혼동 할 수 있어 이에 대해 추가 설명하자면, 앞서 확인했던 MIME 으로 변환된 Body 영역의 문자열 데이터 자체는 Content-Transfer-Encoding 값인 base64로 인코딩 되었다는 의미이다. 그리고 해당 Body 문자열을 base64로 디코딩 할 경우, HTML 문자열 데이터를 다시 얻을 수 있는데, HTML 문자열 자체의 인코딩이 Content-Type의 charset에 작성된 utf-8이라는 의미이다.
추가로, 만약 HTML 본문 데이터를 JavaScript 문자열에서 처리한 뒤 별도의 인코딩이 없었다면 Content-Type의 charset parameter는 JavaScript 문자열의 인코딩인 “utf-16″이 되어야 한다. (utf-8 형식을 사용하고 싶다면 추가적인 인코딩 과정을 거쳐야 한다.)
HTML 데이터에서 리소스를 참조한다면 MHTML에서 본 예제들과 같은 형태로 Header 문자열을 구성해야 한다. 먼저 Content-Type: multipart/related; 가 작성되어야 하며, 각 entity를 구분해줄 boundary parameter값이 작성되어야 한다.
이후 각 Entity는 해당 boundary parameter로 구분되며, Entity별로 Header가 작성되어야 한다. 본문에 해당하는 영역은 앞선 text/html과 동일한 형태로 Header를 작성하며, 그 외 참조되는 각 리소스 별로 Content-Type / Content-Transfer-Encoding / Content-ID / Content-Location 필드를 작성하면 된다. 이때 참조되는 데이터의 미디어 타입은 데이터를 참조하는 각 HTML 태그를 통해 유추할 수 있다.
※ Content-ID를 추가하는 예: Content-ID: <cafe_image_0@s-core.co.kr>
4) HTML 본문 데이터 및 리소스 데이터 인코딩
각 Header에 맞는 실제 데이터를 Body영역에 추가해야 한다. 이때 원문 HTML에서 참조하는 리소스가 다른 Entity에서 Content-ID를 통해 정의되었다면, 원문 HTML 데이터의 리소스를 참조 구문의 내용도 함께 변경되어야 한다.
※ 원문의 변경된 리소스 참조 예: <img src=”cid:cafe_image_0@s-core.co.kr“>
HTML 본문과 모든 리소스가 이메일 메시지에 정상적으로 포함되기 위해서는IMF 항목에서 소개한대로, 메일의 본문 컨텐츠는 7bit의 US-ASCII 문자범위에서 표현 가능형식으로 인코딩 되어야 한다. 이때 MIME(또는 각 Entity)의 Content-Transfer-Encoding에 정의된 방식에 맞게 실제 데이터를 인코딩하면 된다.
※ 앞선 예시에서 작성된 이미지 리소스는 이미 base64 인코딩 된 데이터이므로 별도의 인코딩이 필요하지는 않다.
※ JavaScript에서는 Base64인코딩을 위한 내장함수(인코딩: btoa / 디코딩: atob)를 제공하는데, 막상 2byte를 통해 표현되는 유니코드가 포함된 문자열은 해당 함수를 통해 처리하지 못한다. 이를 위해 결과적으로 JavaScript 변수에 저장된 HTML 문자열을 utf-8로 변환한 뒤, btoa를 통해 인코딩하게 된다.
5) MIME Header와 Body 합치기
MIME( 또는 각 Entity)의 Body를 올바르게 인코딩 한 뒤,, MIME 형식에 맞게 Header와 Body를 합치면 MHTML 데이터가 완성된다.
MHTML 데이터 변환 예시
에스코어의 HTML5 규격 웹 에디터인 CafeNote에서 간단하게 본문과 이미지를 작성한 뒤, 해당 본문을 MHTML로 추출하면 아래와 같은 결과를 확인해 볼 수 있다.
1) 편집창 본문 작성
2) API를 통한 데이터 추출(café.encodeMHTMLFromEditor)
마치며
MHTML로 저장된 파일은 별도의 뷰어가 없더라도 브라우저에서 직접 렌더링이 가능하며, MHTML 형식 파일에 포함된 데이터들이 구조적으로 분리되어 있기 때문에, 직접 데이터를 확인하기도 편리한 형식이다.
다만 현실적으로는 포털에서 제공하는 이메일 서비스를 활용하거나 Outlook등의 이메일 어플리케이션을 활용하기 때문에, MHTML 형식 데이터를 직접 접하고 다룰 일은 많지 않다.
그러나 별도로 이메일을 저장하여 관리하거나 이메일 상의 데이터를 확인해야 할 필요가 있을 때, 이 내용이 조금이나마 도움이 되었으면 한다.
# References
- https://www.iana.org/assignments/media-types/media-types.xhtml
- https://datatracker.ietf.org/doc/html/rfc2045
- https://datatracker.ietf.org/doc/html/rfc2049
- https://datatracker.ietf.org/doc/html/rfc2557
- https://datatracker.ietf.org/doc/html/rfc5322/
- https://developer.mozilla.org/en-US/docs/Web/API/btoa
- http://cafenote.io/cafeNoteEx

이용희 프로
소프트웨어사업부 플랫폼사업팀
에스코어 개발플랫폼그룹에서 웹 에디터 개발 및 기술지원 업무를 하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.