설비 S/T 산출 방법 별 정확도 점검 방안
비즈니스 혁신을 위한 디지털 트랜스포메이션이 주목 받고 있고 관련된 프로젝트도 많이 진행되고 있거나 계획 중이다. 데이터 기반의 프로세스 혁신은 디지털 트랜스포메이션의 필수 과제로 운영정보가 중요한 역할을 담당한다.
본 리포트에서는 비즈니스 프로세스를 혁신하는 운영정보 중 자동 산출 운영정보의 산출 및 정확도 점검 방안을 예시로 들어 자동 산출된 운영정보를 보다 정확하고 효율적으로 사용하기 위한 방안을 제시하고자 한다.
운영정보의 정의 및 자동산출 체계
기준정보란 용어를 범용적으로 사용하면서 그 정의에 대해서 이제는 많이들 이해를 하고 있어, 기준정보 중 운영정보에 대한 정의를 아래의 표로 대신하겠다.
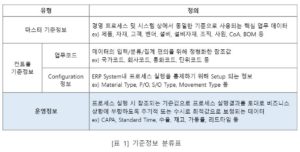
운영정보 자동산출 체계는 3단계로 구현할 수 있다. 아래의 그림 1을 기준으로 1단계는 실적 집계부터 자동산출까지의 운영정보 자동산출 시스템을 구축하고, 2단계는 모니터링 및 분석까지의 지표 정의를 통한 운영정보의 자동 모니터링 체계를 구축한 이후, 마지막 3단계는 Machine Learning 등을 활용한 운영정보의 정확도 개선을 할 수 있다. 3단계는 운영정보의 안정적 산출/관리 이후의 최적화를 위한 단계로 많은 시간이 소요되는 과정으로 본 기고에서는 2단계의 지표 정의를 통해 자동 산출된 운영정보의 신뢰성/정확도를 확보하는 방안에 대해 많이 사용하는 운영정보 중 하나인 표준시간(이하 S/T(Standard Time))을 예시로 설명하겠다.
S/T의 산출 방법
제조현장에서 S/T라고 하면 보통의 숙련 작업자가 정해진 표준의 방법으로 정해진 환경조건 하에서 정해진 설비, 치공구를 활용하여 정상적인 컨디션에서 정해진 작업 순서에 따라 제품 1개를 완성하는데 소요되는 단위당 시간을 말한다. 설비가 생산을 담당하는 현장은 작업자 대신 설비를 대입해도 그 의미가 다르지 않는다. 활용 측면에서 S/T는 생산계획을 수립하거나 설비종합효율을 계산하는데 필요한 Input 정보로 주로 사용되고 있다. S/T의 산출 방법에는 여러 가지가 있지만, 설비 S/T의 산출방법 관점에서 구분하면 자동 S/T, 로직 S/T 및 수동 S/T로 구분할 수 있다.
자동 S/T
자동S/T는 설비자체에서 S/T를 산출한다. 설비의 순작업시간과 설비에 입력된 Lot수량을 계산하여 단위당 S/T를 산출하고 산출된 정보를 S/T를 관리하는 시스템에 전달하게 되고 S/T관리 시스템은 설비생산성 등을 관리하는 시스템에 정보를 제공하여 S/T를 활용하게 된다. 자동S/T는 설비에서 산출되는 정보로 장점이 많지만 단점도 있다. 바로 투자비이다. 삼성전자 같은 Global 대기업은 워낙 고가의 최신 설비를 사용하기 때문에 투자비에서 자유롭지만, 그렇지 않은 많은 설비 중심의 제조업체에서 사용하는 설비는 자동화가 미흡하여 설비에 자재가 투입/배출되는 시점 및 설비의 각 단위 동작(Parameter)별 시간 등이 자동으로 설비에 저장되지 않는 경우도 많다. 이런 경우 S/T를 측정할 수 있는 방법이 로직 S/T와 수동 S/T이다.
로직 S/T
로직 S/T는 설비의 제조작업을 기반으로 동작 단위로 구분하여 수식으로 S/T를 산출하도록 Logic를 작성하여 S/T를 산출 및 관리하는 방법이다. 예를 들어 절단 공정의 경우 1컷을 하는 Cycle time과 부가 시간 등이 로직 S/T의 Factor가 될 수 있고, 전극공정의 경우 도포시간, 장입량 및 로딩율 등이, 도금 공정의 경우는 Barrel 사이즈 등이 Factor가 될 수 있다. 물론 S/T를 산출하는 로직이 단순히 Factor만 선정한다고 되는 것은 아니고, 해당 공정의 숙련된 엔지니어들이 협의 및 테스트를 통해 결정해 나가야 하는 어려움도 있지만, 수동 S/T에 비해 정확도가 높고, 한번 로직을 정해 놓으면 동일 설비나 동종 설비가 들어왔을 때도 적용이 비교적 용이하다는 장점도 있다.
수동 S/T
수동 S/T는 말 그대로 수작업으로 S/T를 측정하는 방식으로 Lot단위로 10회 이상 측정(또는 설비에 디스플레이 되는 값 등 확인) 한 후 최대 · 최소값을 제외한 평균 값을 사용하는 방식 등을 취한다. 수동 S/T는 측정 시마다 값의 변동이 있고, 소량 Lot의 측정 시에는 신뢰성이 떨어진다는 단점이 있다. 산출 자동화 측면에서 자동 S/T와 로직 S/T를 자동으로 산출되는 S/T라고 정의하고, 수동 S/T를 수동으로 산출되는 S/T라고 정의할 수 있다.
산출 정확도 이슈
이렇게 다양한 방법으로 산출된 S/T는 현장에서 문제없이 잘 사용될까? 수동 S/T는 차치하고 자동 산출되는 S/T는 정확도에 문제가 없을까? 자동으로 산출된 S/T도 정확도 관련한 이슈가 있거나 정확도를 검증할 방법이 없어 사용이 저하되는 경우가 발생한다. 그럼 그 이유와 해결 방법은 어떻게 될지 알아보겠다.
운영정보의 정확도 점검 방안 예시
우선 자동 산출하는 S/T는 왜 자동으로 산출할까? 그 이유는 주로 산출 주기가 짧고, 산출 대상이 많아 사람이 일일이 확인해가며 산출하기가 어렵거나 비용이 많이 발생하기 때문이다. 따라서 자동 산출된 S/T는 그 정확도 여부 또한 사람이 일일이 점검하기 어렵다. 그래서 필요한 것이 지표이다.
자동 S/T의 정확도 점검 방안
이론적으로 설비에서 S/T를 자체로 추출하는 자동 S/T는 정확하지 않기가 어렵다. 설비 자체에서 정확한 순작업시간 등을 자동적으로 취합하기 때문이다. 자동 S/T의 정확도에 오류가 생기는 이유는 설비 외적인 부분 때문이다. Lot분할, Lot통합 등이 대표적이다. 설비의 순작업시간은 설비 자체에서 정확하게 측정이 되기 때문에 오류가 없었다. 하지만 Lot단위 생산수량은 공정별 특성에 따라 Lot분할이나 Lot통합 등이 발생할 수 있고, 이 경우 변경된 Lot정보가 제대로 설비에 입력되지 않으면 결과적으로 자동 S/T에 오류가 날 수 있다. Lot분할은 Lot의 생산수량이 줄어 들게 되어 단위당 S/T를 높이게 되고, Lot통합은 반대로 S/T를 낮추게 된다. 확인해야 할 S/T가 많은 상황에서 산출된 자동 S/T값을 대상으로 이를 선별하기는 쉽지 않다. 이럴 경우 지표를 활용하여 S/T의 정확도를 점검할 수 있다.
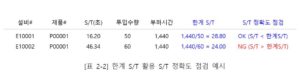
아래 표2-1은 자동 S/T가 산출된 결과 중 오류가 있는 결과이다. 설비 E10001은 정상적으로 S/T가 산출된 걸로 보이지만, 설비 E10002는 동일 제품을 생산하는데 다른 설비보다 2배 이상의 S/T가 산출되었다. 만약 이렇게 S/T의 오류가 발생하고 그 대상 설비나 제품이 아주 많다면 아래 표에서 보이는 것처럼 오류를 바로 집어 내기가 쉽지 않다. 이 경우는 한계 S/T라는 개념의 지표를 생각해 볼 수 있다.

한계 S/T는 부하시간을 투입수량으로 나눈 값으로 이론적으로 나올 수 있는 최대 S/T값으로 산출된 S/T가 이 한계 S/T보다 높을 수 없다. 따라서 아래 표2-2에 있는 E10002설비의 S/T는 잘못 산출된 값이라는 것을 알 수 있고, 대량의 데이터를 대상으로도 같은 지표를 활용하여 오류 대상을 추출할 수 있다.
로직 S/T의 정확도 점검 방안
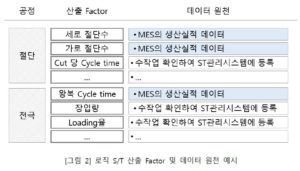
자동 S/T와 다르게 로직 S/T의 정확도 점검은 산출된 결과를 대상으로 하기 어렵다. 대신 로직을 구성하는 산출 Factor별 세부 검증이 필요하다. 그림 2의 절단 공정의 산출 Factor는 세로 절단수, 가로 절단수, Cut당 Cycle time 등 여러 가지이고 그 데이터의 원천은 MES의 생산 실적(생산 실적 저장 시, 관련 Factor값 자동 저장 or 수작업 필수 입력)이나 ST관리 시스템에 수작업 등록(설비의 개조/개선 등 변경점 발생 시 ST관리 시스템에 Factor 값을 등록) 하는 것이다. 이 중, MES의 생산실적 데이터를 사용하는 산출 Factor는 MES의 생산실적 데이터 값과 산출 Factor의 값이 같은지 여부를 확인할 수 있는 지표를 개발하여 로직 S/T의 정확도를 점검할 수 있다. 당연히 같을 것 같지만 확인해보면 의외로 많은 경우에 해당 데이터와 산출 Factor간 값 차이가 많은 경우가 자주 발생한다.
운영정보의 정확도 점검 방안 적용
지금까지 자동 S/T와 로직 S/T의 정확도를 점검하기 위해 지표를 사용하는 방법을 예시를 들어 설명했다. 그럼 실제로 이 지표들을 적용하기 위해 어떤 시스템을 적용해야 할까?
DQM을 활용한 시스템 적용
DQM(Data Quality Management)은 기준정보의 품질을 관리하는 시스템이다. MDM(Master Data Management)을 구축한 기업 중 데이터 품질관리를 위해 주로 도입하는 시스템이고, 데이터 품질관리를 위해 정의된 지표를 기준으로 데이터를 정기적으로 모니터링하여, 해당 지표 값과 오류 데이터를 사용자에게 제공하여 사용자가 품질 트랜드 및 오류 데이터만을 취합하여 관리할 수 있게 한다. 주로 마스터 데이터의 품질관리를 위해 사용되지만, 운영정보도 앞에서 언급한 지표들을 정의하여 적은 노력으로 데이터의 정확도를 모니터링하고 관리할 수 있을 것이다.
마치며
앞서 살펴본 바와 같이 운영정보를 산출하고 산출 결과를 검증하여 정확도를 제고하고, 그 운영정보를 사용하는 프로세스나 시스템의 Output을 개선한다면, 그것 자체가 프로세스 혁신의 과정이라고 할 수 있다. 일관되고 정확한 정보 획득으로 더 많은 업무개선 기회가 주어질 것이고, 보다 정확한 분석 결과를 얻게 되면서 프로세스 혁신의 성공 가능성을 한층 높일 수 있을 것이다.
데이터가 점점 중요해지는 디지털 트랜스포메이션의 시대에, 전사적으로 산출/관리해야 할 운영정보는 점점 많아지고, 데이터 정확도에 대한 요구사항도 점점 높아지는 상황에서, 데이터를 잘 활용하기 위한 기업들의 노력이 좋은 결실을 맺어 혁신 성장의 기틀을 세우기를 기원하겠다.

오장근 상무
에스코어㈜ 컨설팅사업부 데이터컨설팅팀
프로세스 혁신(PI) 및 데이터 컨설팅을 담당하고 있으며, 삼성 관계사와 국내 주요 대기업을 대상으로 다수의 프로젝트 경험을 가진 전문가입니다.
-
다음 글



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.