들어가며
AI 에이전트와 실시간 AI 검색 서비스의 중요성이 커짐에 따라, 대규모 언어 모델(LLM, Large Language Model)의 ‘확률적 앵무새(stochastic parrot)[1]‘ 한계를 극복하려는 노력이 지속되고 있다. 대규모 언어 모델은 확률 기반으로 답변을 생성하기 때문에, 때때로 근거가 불명확한 출력을 내놓을 수 있다. 이를 보완하기 위해 검색 증강 생성(RAG, Retrieval-Augmented Generation)과 같은 보조 기법이 활용된다. 특히, 하이브리드 검색은 정확성과 유연성을 동시에 제공하는 특징이 있어 검색 증강 생성 기술과 결합될 경우 사용자의 검색 경험을 향상시키고 대규모 언어 모델 시스템의 성능을 최적화하는 데 기여할 수 있다.
[1] 기계 학습에서 대형 언어 모델이 그럴듯한 언어를 생성할 수 있지만 자신이 처리하는 언어의 의미를 이해하지 못한다는 이론을 설명하는 비유이다. 이 용어는 Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Margaret Mitchell의 2021년 논문 “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? 🦜”에서 처음 사용되었다.
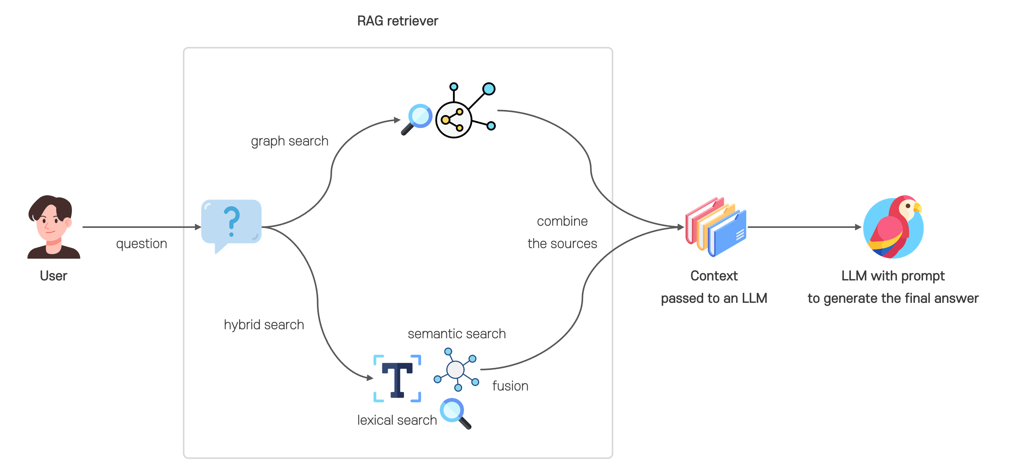
[그림 1] 하이브리드 검색이 적용된 RAG
본 글에서는 하이브리드 검색의 필요성, 핵심 개념, 실무 적용, 모범 사례 및 성능 평가를 다각도로 살펴보며, 독자의 이해를 돕고자 한다.
하이브리드 검색의 필요성
어휘 검색(lexical search)만으로는 원하는 정보를 찾는 데 어려움을 겪을 수 있다. 예를 들어, 특정 의자에 대한 정보를 찾고자 하지만 정확한 이름이나 브랜드를 모른다고 가정해 보자. 만약 ‘화이트 톤 거실에 어울리고, 나무로 제작되었으며, 팔걸이부터 다리까지 곡선 형태로 이어진 디자인에, 검은색 쿠션이 있고 약간 뒤로 기대어지는 의자’를 찾고자 한다면, 어떤 검색어를 입력해야 할까? 일반적으로 사용자는 기억하는 특징을 바탕으로 ‘검은색 의자’나 ‘나무 의자’와 같은 키워드를 입력한 후, 검색 결과를 확인하며 원하는 제품을 찾는다. 또는 색상, 소재, 형태 등을 필터링 기능을 이용해 선택하여 검색할 수도 있다. 하지만 이러한 키워드 매칭 방식에 의존하면 원하는 결과를 찾기까지 시간이 오래 걸리고, 정확한 정보를 제공받지 못할 가능성도 있다.
반면, 의미 검색(semantic search)은 대상의 특징은 알지만 구체적인 지칭을 모를 때 유용하다. 의미 검색은 단순한 키워드 매칭을 넘어, 검색어의 문맥을 반영하여 더 적합한 결과를 제공한다. 벡터 임베딩을 활용해 검색어의 의미를 고려하여 보다 정확한 결과를 도출하는 방식이다. 예를 들어, 위에서 언급한 의자에 대한 문장을 그대로 입력하면, 정확한 모델명을 몰라도 유사한 디자인이나 스타일의 의자를 추천 받을 수 있다. 그러나 의미 검색에도 한계가 있다. 문맥을 중시하는 만큼, 중요한 키워드를 놓치거나 원하지 않는 항목이 포함될 수 있다. 예를 들어, ‘검은색 쿠션’이나 ‘나무로 제작된’ 다른 물체들이 검색 결과에 포함될 수 있다. 즉, 의미 검색은 검색 범위를 넓히는 데 유용하지만, 정확도를 높이는 데는 한계가 있다.
이러한 한계를 극복하기 위해 하이브리드 검색(hybrid search)이 등장했다. 하이브리드 검색은 키워드 검색과 의미 검색을 결합하여 두 방식의 장점을 모두 활용한다. 의미 검색은 문맥을 반영하면서도, 키워드 검색은 과도하게 확장된 검색 범위를 조정해 더 정확한 결과를 제공한다. 즉, 위의 의자를 검색할 때, 의미 검색은 전체적인 문맥을 반영하고, 키워드 검색은 핵심 특징을 포착하여 원하는 의자가 검색 결과 상위에 노출될 수 있도록 한다.
하이브리드 검색의 핵심 개념
하이브리드 검색은 여러 검색 방식을 결합하여 각 방식의 장점을 최대한 활용하는 기술이다. 일반적으로 어휘 검색과 의미 검색을 함께 사용하며, 이를 효과적으로 구현하기 위해 각 방식이 검색어(query)와 문서(document)의 관련성(relevance)을 어떻게 평가하는지 이해하는 것이 중요하다.

[그림 2] 하이브리드 검색 과정
어휘 검색은 검색어와 정확히 일치하는 용어가 특정 문서에서 자주 등장하고, 다른 문서에서는 드물게 나타날수록 관련성이 높다고 평가한다. 이를 위해 주로 TF-IDF(Term Frequency-Inverse Document Frequency)와 이를 개선한 BM25(Best Matching 25) 알고리즘이 사용된다. 검색어와 문서를 토큰화(tokenization)하고 정규화(normalization)하여 용어(term)을 생성한 후 검색을 수행하는 방식이다. 어휘 검색은 입력된 키워드와 일치하는 문서를 효과적으로 찾아낼 수 있다. 유사한 의미를 가진 다른 표현이 포함된 문서는 동의어 토큰 필터(synonyms token filter)를 통해 일부 해결할 수 있다. 그러나, 이러한 필터를 효과적으로 사용하려면 관리자가 주기적으로 업데이트해야 하는 한계가 있다.
의미 검색은 검색어와 문서를 벡터로 변환한 후, 두 벡터 간 유사도를 계산하여 의미적으로 가까운 문서를 찾는다. 벡터 임베딩(vector embedding)을 활용해 텍스트를 고차원 공간에서 표현하며, L2 거리(Euclidean distance)나 코사인 유사도(cosine similarity) 등을 이용해 유사도를 측정한다. 이 과정에서 k-NN(k-Nearest Neighbors) 또는 연산 속도를 개선한 ANN(Approximate Nearest Neighbor) 탐색 기법이 자주 활용된다. 의미 검색은 다양한 표현을 가진 검색어에 대해 보다 관련성 높은 결과를 제공할 수 있다. 하지만, 그 정확도는 사용된 임베딩 모델과 데이터 품질에 크게 의존한다.
하이브리드 검색은 어휘 검색과 의미 검색을 조합하여 두 방식의 장점을 극대화하는 기술이다. 일반적으로 각 문서의 점수를 특정 수식을 통해 재정렬하여 최종 검색 결과를 생성하며, 대표적인 결합 방법으로 CC(Convex Combination)와 RRF(Reciprocal Rank Fusion)가 있다.
CC는 각 검색 방식의 점수(score)를 선형 결합(linear combination)하여 최종 순위를 결정하는 방식이다. 이 과정에서 점수를 정규화(normalization)하고 가중치(weight)를 적용하여 각 방식의 기여도를 조정한다. 최적의 가중치를 설정하는 과정(calibration)이 필요하지만, 특정 검색 방식의 중요도를 조절할 수 있는 유연성을 제공한다.

[수식 1] CC의 계산식
RRF는 개별 검색 방식의 순위(rank)를 결합하는 기법이다. 각 검색 방식의 결과 순위를 기반으로 역순위(reciprocal rank)를 계산하고 이를 합산하여 최종 점수를 도출한다. 여기서 사용되는 상수 k(rank constant)는 작은 순위 값이 검색 결과에 미치는 영향을 완화하는 역할을 한다. 점수 대신 순위 정보만 활용하며, 가중치 조정 과정 없이도 간편하게 양호한 성능을 제공하는 방식으로, 다양한 검색 방식을 빠르게 결합할 때 유용하다.

[수식 2] RRF의 계산식
하이브리드 검색의 실무 적용
최근 다양한 검색 엔진과 벡터 DBMS가 하이브리드 검색 기능을 지원하고 있다. 특히 Elasticsearch와 OpenSearch를 활용한 하이브리드 검색 솔루션은 효율적이며 성능 면에서도 뛰어난 선택지가 된다. 이 두 시스템은 어휘 기반 검색에서 입증된 성능을 자랑하며, 우수한 한국어 분석 기능도 제공한다. 기존의 강력한 어휘 검색 기능에 기본 제공되는 임베딩 모델을 활용한 의미 검색 기능을 결합하면, 검색 성능과 정확도를 모두 만족시키는 최적의 하이브리드 검색 솔루션을 구현할 수 있다.
Elasticsearch의 하이브리드 검색은 구성의 간편함과 뛰어난 성능을 제공한다. 기본 제공하는 ELSER(Elastic Learned Sparse EncodeR)는 빠르고 효율적인 희소 인코딩 모델(sparse encoding model)로, 약 30,000개의 방대한 어휘 집합(vocabulary)을 활용해 특정 도메인 외 환경(out-of-domain)에서도 안정적인 성능을 보인다. E5(EmbEddings from bidirEctional Encoder rEpresentations)는 다국어(multilingual) 텍스트 임베딩 모델(text embedding model)로, ELSER가 영어 텍스트 처리에 강점을 가진다면, E5는 여러 언어 간 의미 유사성을 효과적으로 반영할 수 있다. 이러한 임베딩 모델을 활용해 의미 검색을 구현하고, BM25를 이용한 어휘 검색과 CC 방식으로 가중치를 조절하거나, RRF 방식을 적용해 간편하고 성능이 뛰어난 하이브리드 검색을 구성할 수 있다.
OpenSearch의 하이브리드 검색은 높은 커스터마이징 자유도를 제공한다. 기본적으로 Hugging Face의 SBERT(sentence transformer) 텍스트 임베딩 모델을 지원하며, 자체 학습된 희소 인코딩 모델도 제공한다. 또한, 벡터 유사도 측정 지표, ANN 기법, ANN 지원 라이브러리 등을 세부적으로 선택할 수 있어 다양한 검색 환경에 맞춰 최적화할 수 있다. BM25 기반의 어휘 검색과 텍스트 임베딩을 결합할 수 있고, 희소 인코딩 모델과 텍스트 임베딩 모델을 조합하는 것도 가능하다. CC 방식에서는 산술 평균(arithmetic mean), 기하 평균(geometric mean), 조화 평균(harmonic mean) 중 선택할 수 있으며, 검색 결과 정규화 방법도 L2 정규화와 최소-최대(min-max) 정규화 중 선택 가능하다. 이러한 커스터마이징 옵션을 활용하면 최적의 검색 성능을 얻을 수 있다.
Elasticsearch와 OpenSearch 사례에서 볼 수 있듯이, 검색 엔진과 벡터 DBMS는 강력한 의미 검색 기능을 제공하기 위해 다양한 방식으로 임베딩 모델을 활용한다. 일반적으로 내장 모델(built-in model)을 기본 제공하며, 외부 서드파티 서비스(예: Hugging Face)에서 호스팅된 모델(externally hosted model)을 가져와 사용할 수도 있고, 사용자가 직접 훈련한 사용자 정의 모델(custom upload model)을 업로드하는 방식도 가능하다.
하이브리드 검색 환경에서 최적의 모델을 선택하려면 성능, 비용, 신뢰성 등을 신중하게 고려해야 한다. 특히, 사용할 모델이 한국어 벡터 임베딩을 효과적으로 지원하는지, 라이선스 조건이 적절한지, 유료 서비스 여부 등을 면밀히 검토해야 한다. 이를 통해 도메인 특성에 맞는 최적의 검색 솔루션을 구축할 수 있다.
하이브리드 검색의 성능 평가
많은 검색 엔진과 벡터 DBMS는 하이브리드 검색 기능의 성능을 다양한 구축 환경과 구성 요소를 통해 평가하고 공개하고 있다. 그중 OpenSearch blog의 “Improve search relevance with hybrid search, generally available in OpenSearch 2.10” 글에서는 OpenSearch를 활용한 어휘 검색, 의미 검색, 하이브리드 검색의 벤치마크 결과를 제시한다. 하이브리드 검색은 커스터마이징 요소가 많아 성능 최적화를 위한 다양한 접근이 가능하므로, 이 벤치마크는 향후 성능 개선을 위한 주요 기준점으로 활용될 수 있다.
벤치마크는 OpenSearch v2.10에서 수행되었으며, 클러스터는 3개의 r5.8xlarge 데이터 노드와 1개의 c4.2xlarge 리더 노드로 구성되었다. 하이브리드 검색은 어휘 검색과 의미 검색을 결합하는 방식으로, 어휘 검색에는 영어 분석기(English Analyzer)가 사용되었으며, 의미 검색에서는 HNSW 알고리즘의 k 값을 100으로 설정하였다. 데이터 세트는 의학(NFCorpus), COVID-19 연구(Trec-Covid), 과학 문헌(Scidocs), 질문-답변(Quora), 전자상거래(Amazon ESCI) 등 다양한 도메인으로 총 7개가 사용되었다.
검색 품질 평가는 nDCG@10(Normalized Discounted Cumulative Gain at 10)이 사용되었다. 이는 상위 10개 검색 결과의 순위와 관련성을 동시에 고려하여 검색 품질을 0에서 1 사이의 값으로 평가하는 지표로, 1에 가까울수록 이상적인 검색 결과에 근접한다. 이를 백분율로 환산하면 검색 결과가 최적 수준의 몇 퍼센트에 해당하는지를 파악할 수 있다. nDCG는 MTEB(Massive Text Embedding Benchmark) 리더보드와 같은 벤치마크에서 검색 성능 평가 지표로 자주 활용되며, 검색 결과의 순위와 관련성을 함께 고려한다는 점에서 다른 지표보다 정교한 평가를 제공한다.
실험 결과, 검색 품질 평가는 하이브리드 검색이 어휘 검색 대비 8~12%, 의미 검색 대비 15% 더 나은 검색 품질을 제공하는 것으로 나타났다. 의미 검색은 어휘 검색보다 평균 6.97% 낮은 성능을 보였으나, 파인 튜닝(fine-tuning)을 적용한 하이브리드 검색은 어휘 검색 대비 평균 12.08% 높은 성능을 기록하며 가장 우수한 결과를 나타냈다. 이는 하이브리드 검색이 어휘 검색과 의미 검색의 장점을 결합하여 더욱 정확하고 관련성 높은 검색 결과를 제공함을 입증한다. 특히, 파인 튜닝을 적용한 하이브리드 검색은 검색 시스템의 품질 개선에 큰 기여를 할 수 있음을 보여준다.

[표 1] OpenSearch v2.10 하이브리드 검색 품질 평가 결과
처리 시간 평가는 하이브리드 검색 기능이 지원되기 전, 유사한 방식으로 구현된 불린 쿼리(boolean query)를 기준으로 삼아 하이브리드 쿼리(hybrid query)의 처리 시간을 밀리초(ms) 단위로 측정 및 비교하였다. 분석 결과, 하이브리드 쿼리는 불린 쿼리보다 전반적으로 처리 시간이 증가한 것으로 나타났다.
p90 지표(요청의 90%가 처리되는 최대 시간)에서 하이브리드 쿼리는 불린 쿼리 대비 평균 6.96% 증가했으며, p99 지표(요청의 99%가 처리되는 최대 시간)에서는 8.27% 증가했다. 이러한 처리 시간 증가는 하이브리드 쿼리가 어휘 검색과 의미 검색을 결합하는 과정에서 점수 정규화 및 결과 조합과 같은 추가 연산을 수행하기 때문이다.
그러나 이러한 처리 시간 증가는 허용 가능한 수준이며, 향상된 검색 관련성이 이를 충분히 보완할 수 있다. p99에서 처리 시간이 가장 많이 증가한 DBPedia 데이터 세트의 경우만 보더라도, 하이브리드 쿼리을 통해 0.024초의 추가 처리 시간이 발생했지만, 불린 쿼리로는 얻을 수 없는 최적의 검색 방식 조합을 제공할 수 있기 때문이다.

[표 2] OpenSearch v2.10 하이브리드 검색 처리 시간 평가 결과
하이브리드 검색의 모범 사례
하이브리드 검색을 실무에 적용하면 다양한 방법을 통해 검색 성능을 최적화 할 수 있다. 기본적으로, 검색 엔진의 성능을 극대화하기 위해 컴퓨팅 리소스, 샤드(shard) 및 인덱스(index) 최적화 등을 고려하여 실무 환경에 최적화된 검색 서비스를 설계하고 구축하는 것이 중요하다. 그 후, 어휘 검색과 의미 검색의 조합 방식과 최적의 설정을 탐색하여 하이브리드 검색의 효과를 극대화하는 접근이 필요하다.
하이브리드 검색은 어휘 검색과 의미 검색을 결합하는 과정에서 다양한 요소를 커스터마이징 할 수 있어, 최적의 성능을 달성하기 위한 여러 조합을 시도할 수 있다. 주요 결합 방식으로는 CC와 RRF가 있으며, CC에서는 평균 수식과 가중치 조정을 활용해 유연한 조합이 가능하다. 어휘 검색의 경우, 캐릭터 필터(character filter), 토크나이저(tokenizer), 토큰 필터(token filter) 등을 조정하여 쿼리 성능을 최적화할 수 있다. 의미 검색에서는 벡터 유사도 측정 방식(L1, L2, L-infinity norm, 코사인 유사도, 내적 등)을 선택할 수 있고, ANN 기법으로 HNSW, IVF 등의 알고리즘을 적용할 수 있다. 또한, NMSLIB, FAISS, Lucene 등의 라이브러리를 활용하여 최적화된 검색 성능을 확보할 수 있으며, 벡터 양자화(vector quantization)를 적용해 메모리 사용량을 최적화 할 수도 있다.
하이브리드 검색을 효과적으로 활용하려면 도메인에 최적화된 파인 튜닝이 필수적이다. 어휘 검색에서는 동의어 토큰 필터를 적용하여 유사한 검색어를 처리할 수 있지만, 관리자가 주기적으로 업데이트해야 하는 부담이 있다. 의미 검색은 다양한 도메인에 적용할 수 있지만, 최적화되지 않은 경우 동의어나 유사 표현을 효과적으로 반영하지 못할 수 있다. 이를 보완하기 위해 의미 검색의 임베딩 모델을 파인 튜닝하고, 어휘 검색에서는 동의어 필터를 강화하는 방식으로 도메인 적합성을 높여야 한다.
파인 튜닝이 자주 이루어진다면, 자동화된 임베딩 모델 학습 시스템을 도입하는 것도 생각해 볼 수 있다. 데이터 세트가 확장됨에 따라 의미 검색에서 사용하는 임베딩 모델은 지속적인 업데이트와 재색인(reindex)이 필요하다. 이를 효과적으로 관리하기 위해 벡터 임베딩 모델을 구축, 훈련, 배포할 수 있는 플랫폼을 활용하면 모델 학습 및 최적화를 자동화할 수 있다. 이러한 자동화된 시스템을 통해 최신 상태의 임베딩 모델을 유지하고, 필요 시 신속하게 재훈련 및 재색인을 수행할 수 있다.
또한, 하이브리드 검색을 동적으로 구성하는 방식도 고려할 수 있다. 검색어의 글자 수, 단어 수, 특수문자 포함 여부, 언어 구분 등의 특징을 분석(feature engineering)하고, 이를 기반으로 최적의 하이브리드 검색 조합을 예측하는 머신 러닝(machine learning) 모델을 학습시킬 수 있다. 선형 회귀(linear regression)나 랜덤 포레스트(random forest) 모델을 활용하여 가중치 조정, 정규화 및 조합 방법을 자동으로 예측하며, 검색 파이프라인(search pipeline)과 연계하여 실시간으로 최적의 검색 구성을 수행할 수 있다. 이 방식은 검색 성능을 최적화 할 수 있지만, 처리 시간이 증가할 수 있으므로 데이터 세트에 따른 성능 개선 효과를 면밀히 평가해야 한다.
추가적인 검색 성능 향상을 위해 교차 인코더 모델(cross encoder model)을 활용할 수도 있다. 교차 인코더는 검색어와 문서를 하나의 입력으로 사용하여 유사도를 직접 계산함으로써 높은 정확도를 제공하지만, 연산 비용이 크고 대규모 문서에 적용하기 어려운 단점이 있다. 이를 해결하기 위해, 하이브리드 검색을 활용해 초기 검색 결과를 빠르게 필터링한 후, 상위 k개의 문서에만 교차 인코더를 적용하여 보다 정밀한 재순위화를 수행하는 방식(two-stage retrieval)이 효과적이다. 이를 통해 하이브리드 검색의 빠른 속도와 교차 인코더의 높은 정확도를 결합할 수 있으며, 연산 비용을 줄이면서 검색 결과의 관련성을 더욱 향상시킬 수 있다.

[표 3]하이브리드 검색 성능 향상 방안
마치며
하이브리드 검색은 어휘 검색과 의미 검색의 장점을 결합하여 검색 정확도와 다양성을 크게 향상시키는 강력한 방식이다. 이를 통해 문맥을 반영한 의미 검색과 구체적인 키워드 기반의 어휘 검색을 조화롭게 활용함으로써 보다 정밀하고 관련성 높은 검색 결과를 제공할 수 있다. 특히, 대규모 언어 모델과 결합될 경우 더욱 정교한 검색 시스템을 구축할 수 있어, 하이브리드 검색의 중요성은 앞으로 더욱 커질 것이다.
하이브리드 검색을 도입하려는 기업과 개발자들은 사용 사례에 맞는 최적의 조합을 지속적으로 평가하고 개선하는 것이 필수적이다. 기존에 어휘 검색이나 의미 검색 중 하나만 사용하고 있다면, 하이브리드 검색을 도입하여 두 방식의 장점을 결합하는 것을 고려할 만하다. 하이브리드 검색은 다양한 검색 요구를 충족할 수 있는 효과적인 솔루션으로 자리 잡고 있으며, 기술 발전과 함께 더욱 향상된 성능을 제공할 것이다. 이러한 발전은 검색 시스템의 품질을 높이고, 사용자 만족도를 크게 향상시키는 데 중요한 역할을 할 것으로 기대된다.
# References
https://www.elastic.co/search-labs/blog/demystifying-chatgpt-methods-building-ai-search
https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
https://www.elastic.co/search-labs/blog/improving-information-retrieval-elastic-stack-hybrid
https://www.couchbase.com/blog/hybrid-search/
https://www.elastic.co/search-labs/blog/genai-customer-support-building-a-knowledge-library
https://aws.amazon.com/ko/blogs/big-data/hybrid-search-with-amazon-opensearch-service/
https://opensearch.org/blog/hybrid-search/
https://opensearch.org/blog/hybrid-search-optimization/

노동경 프로
소프트웨어사업부 솔루션사업팀
클라우드 네이티브 기반 마이크로서비스 아키텍처 환경에서 디지털 자산 유통을 위한 서비스 플랫폼의 백엔드 개발을 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.