들어가며
생성형 AI 서비스가 우리 생활 여기저기에 활용되면서, GPT와 같은 생성형 모델에 대해서는 익숙하면서도, 임베딩 모델에 대해서는 생소해하는 사람들이 많다. 하지만 임베딩 모델은 오래전부터 데이터 분석 업무에 활용되었으며, 생성형 모델과 함께 쓰이면서 생성형 AI 서비스를 부족한 점을 보완하는 등 주/조연을 가리지 않고 다양한 업무에 활용되고 있다. 본 문서에서는 임베딩 모델을 분류하여 각각의 특징에 대해 살펴보고 앞으로 현업에 적합한 임베딩 모델을 선정하는 방안에 관해 설명한다.
1. 임베딩 모델이란?
“나는 앱 프로그래밍을 선호한다.”라는 문장과 “저는 애플리케이션 개발을 좋아합니다” 문장이 있다. 사람은 두 문장이 유사하다는 것을 쉽게 알 수 있지만 시스템은 입장에서는 쉽지 않다. 형태소 단위나 글자 단위로 비교해도 유사한 글자가 거의 없기 때문에, 단어의 동일성만을 강조하는 전통적인 키워드 방식의 검색을 수행한다면 좋은 결과를 얻기 힘들다. 이럴 때, 벡터 임베딩을 활용한 벡터 유사도 검색(Similarity search 또는 Semantic search)이 힘을 발휘한다.
기계학습에서 임베딩(Embedding)이란 텍스트, 이미지 등의 데이터를 ‘벡터 임베딩 (Vector Embedding)’라고 하는 수치화된 배열로 변환한 방법을 의미한다. 시스템은 이 임베딩을 사용하여 데이터 간의 중요한 패턴이나 관계를 연산할 수 있다. 임베딩 모델(Embedding)은 데이터를 벡터로 변환할 수 있도록 학습된 기계학습 모델을 의미하며, 학습이 잘된 모델일수록 변환된 벡터값끼리의 관계를 잘 표현한다.
예를 들어, 위 문장을 포함한 여러 문자를 임베딩 모델을 통해 벡터 임베딩으로 변환하고 다차원 공간에 배치해 보자. 편의상 벡터를 점(Point)으로 가정한다면, 관련 있는 벡터일수록 더 모여있게 될 것이다. 따라서 위 문장들의 벡터들은 의미상으로 가까운 거리에 위치하며, “나는 앱 프로그래밍을 선호한다.” 문장 벡터를 기반으로 가까운 벡터를 검색한다면 “저는 애플리케이션 개발을 좋아합니다” 문장 벡터가 검색 결과 중 상위에 존재하게 된다.
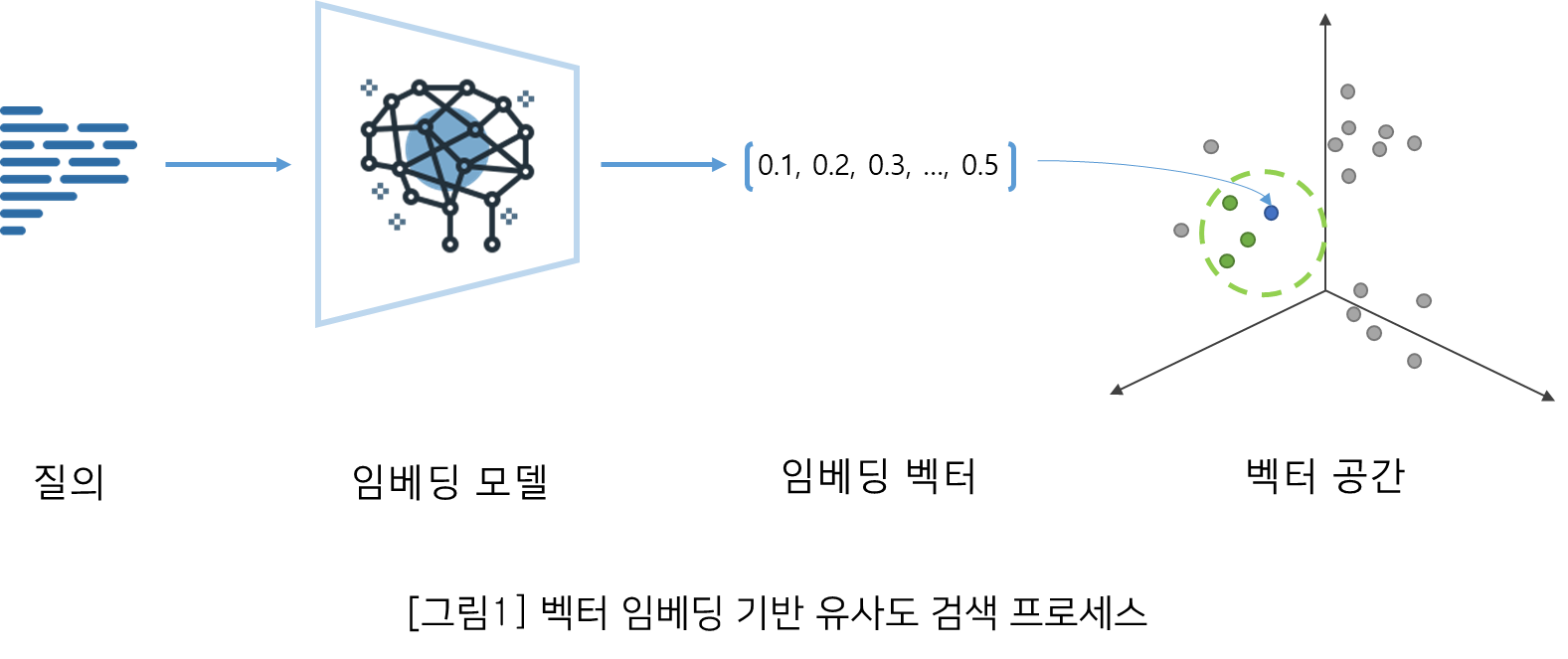
임베딩 모델은 이러한 특징을 바탕으로 검색 용도뿐만 아니라 클러스터링(Clustering), 개인화 서비스 등을 위한 추천(Recommendation), 이상치 탐지(Anomaly detection) 등에 폭넓게 활용되고 있다.
2. 임베딩 모델의 분류
2.1 구조 기반 분류
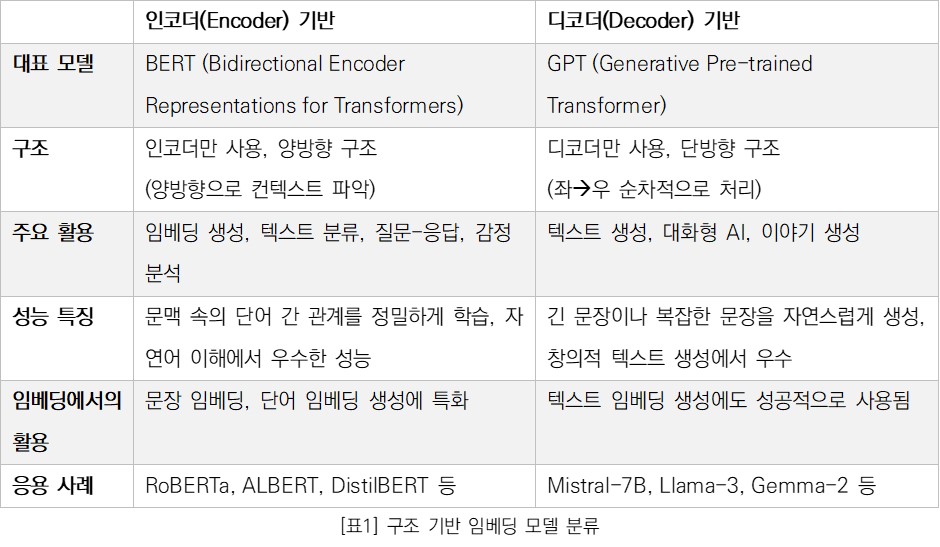
임베딩 모델은 기반이 무엇인가에 따라 크게 인코더(encoder) 기반, 디코더(decoder) 기반으로 나눌 수 있다. 이는 현대 임베딩 모델들이 대부분 트랜스포머(Transformer) 모델 구조에 기반하였기 때문이다.
트랜스포머는 2017년에 발표된 구글의 언어 모델이다. 트랜스포머는 당시 좋은 성능을 보이던 신경망 모델들을 따라 인코더-디코더 구조를 가진다. 인코더는 입력 데이터를 받아들여 중요 정보를 압축한 고차원 벡터(Vector)로 변환하며, 디코더는 이를 기반으로 최종 출력을 생성하는 역할을 한다. 하지만 트랜스포머 아키텍처는 꼭 인코더-디코더 구조에 국한되지 않으며, 인코더만 또는 디코더만 사용하여도 유효한 모델을 만들 수 있다. OpenAI사의 디코더 기반 모델인 GPT(Generative Pre-trained Transformer), 구글사의 인코더 기반 모델인 BERT(Bidirectional Encoder Representations for Transformers)가 그 사례이다. 한동안 GPT 계열과 BERT 계열은 각각의 특성에 맞춰 연구되었으며, BERT 계열의 인코더 기반 모델들이 주로 임베딩 용도로 활용되었다.
그러나 디코더 기반 모델 역시 임베딩을 생성하는 데 성공적으로 사용되고 있다. Mistral사를 비롯한 여러 AI 기업은 디코더 기반의 LLM(거대언어모델: Large Language Model)을 임베딩 모델로 활용하면서 다양한 벤치마크에서 두각을 드러내고 있다.
2.2 라이선스 기반 분류
라이선스 기반 모델 분류는 임베딩 모델뿐만 아니라 생성형 모델까지 모두 적용 가능하지만 여기서는 임베딩 모델에 한정한다.
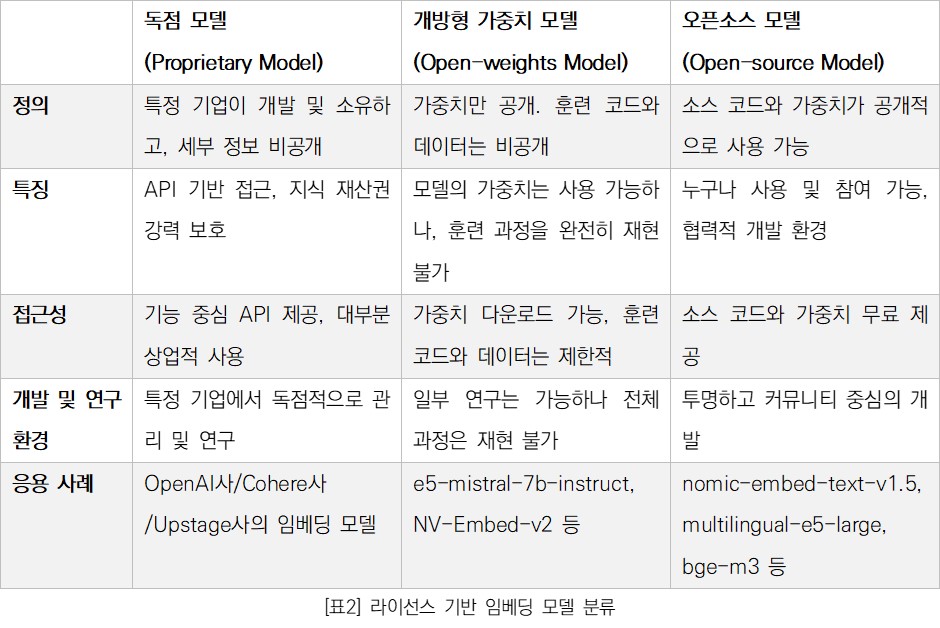
OpenAI사는 AI 모델 서비스의 새장을 열었다. GPT-2까지는 모델과 학습 정보를 공개하였다면, GPT-3부터는 대부분의 정보를 비공개하고 기능 중심의 API 서비스를 실행한 것이다. OpenAI사의 임베딩 모델 역시 세부 정보가 비공개되어 있으며, 공식 문서를 통해서야 그 실체를 일부 가늠해 볼 수 있다. 이러한 모델들을 ‘독점 모델(Proprietary Model)’이라고 하며, 특정 기업이 개발하고 소유한 AI 모델로써, 모델의 용도, 비용, 지식재산권이 강력하게 보호된다. OpenAI사, Cohere사, Upstage사의 임베딩 모델들이 독점 모델에 속한다.
개방형 가중치 모델(Open-weights Model)은 가중치는 공개되어 있지만, 훈련 코드나 데이터 세트은 비공개인 모델을 의미한다. 여기서 가중치(weight)란 학습 과정에서 최적화되는 수치적 매개변수로 모델의 추론 능력에 영향을 끼친다. 사전 훈련된 모델을 다운로드하여 사용할 수 있고, 개인 데이터로 미세 조정하여 특정 작업에 맞게 사용할 수 있지만, 학습 과정을 완전히 재현이 불가하기 때문에 모델을 특정 용도에 맞게 미세 조정(fine-tuning)하기 어렵다. Microsoft 연구소의 e5-mistral-7b-instruct 모델, Nvidia사의 NV-Embed-v2 모델 등과 같이 테스트 세트를 공개하지 않는 모델이 이에 해당한다.
오픈소스 모델(Open-source Model)은 소스 코드와 가중치가 공개적으로 사용할 수 있는 모델이다. Huggingface 같은 플랫폼에서 쉽게 접근할 수 있으며, 누구나 사용 및 참여할 수 있는 환경에서 개발된다. nomic-ai사의 nomic-embed-text-v1.5 모델, Microsoft 연구소의 multilingual-e5-large 모델, 중국 인공지능 아카데미(BAAI)의 bge-m3 모델 등이 이에 해당한다.
3. 임베딩 모델의 발전
임베딩 모델은 그 구조와 라이선스에 따라 구분될 수 있지만, 이러한 구분이 모델 간의 우열을 나타내는 것은 아니다. 오히려 다양한 모델 생태계가 임베딩 모델의 발전을 촉진하고 있으며, 이러한 상호작용은 모델 혁신을 이끌어내고 있다. 이를 잘 보여주는 예로 E5 모델이 있다. E5 모델은 그 발전 과정에서 서로 다른 접근 방식과 다양한 데이터를 통해 성능을 극대화했다.
E5 모델은 최초로 인코더 기반의 구조로 설계되었으며, 자체적으로 정제된 데이터를 활용한 약하게 감독 된 대조 학습(Weakly-Supervised Contrastive Learning) 방식으로 훈련되었으며, 다양한 텍스트 임베딩 작업에서 뛰어난 성능을 보여주었다. 특히, 다양한 자연어 처리(NLP) 과제에서 고품질의 텍스트 표현을 제공하여 그 우수성이 입증되었다. 이때 모델은 주로 인코더-디코더 구조에서 인코더 부분에 집중하여 텍스트를 고차원 벡터로 임베딩하는 데 중점을 두었다.
E5 모델의 다음 단계는 디코더 기반의 대형 언어 모델(LLM)을 적용한 E5-Mistral-7B로 발전했다. 이 모델은 GPT-3.5 Turbo 및 GPT-4와 같은 강력한 LLM을 사용하여 생성된 데이터 세트를 학습에 활용했다. E5-Mistral-7B는 Mistral-7B와 같은 LLM을 기반으로 더욱 확장된 성능을 자랑하며, 특히 더 큰 언어 모델의 이점을 활용하여 더욱 정교한 텍스트 임베딩을 생성할 수 있었다. 이는 인코더 기반 접근을 넘어서 디코더 기반의 잠재력을 극대화한 결과로, 기존의 E5 모델에 비해 다양한 텍스트 표현에서 더욱 높은 성능을 보여주었다.
흥미롭게도 E5의 발전은 다시 인코더 기반 모델로 회귀하는 방식으로 이어졌다. 최신 E5-Large-Instruct 모델은 E5-Mistral-7B가 사용한 데이터 세트를 바탕으로 기존의 인코더 기반 E5 모델을 미세 조정하여 구현되었다. 이 모델은 E5-Mistral-7B와 유사한 수준의 성능을 제공하면서도 인코더 구조의 효율성을 유지했으며, 이를 통해 인코더와 디코더 기반 모델 사이의 상호 보완적 관계를 잘 보여주었다.
E5 모델의 발전사는 단일 모델 구조에 얽매이지 않고, 다양한 모델 구조와 데이터 세트를 결합하여 더 나은 성능을 달성하는 임베딩 모델의 혁신적인 가능성을 보여준다. 이를 통해 인코더와 디코더, LLM과 오픈소스, 다양한 언어 지원을 모두 아우르는 텍스트 임베딩의 미래가 더욱 발전할 수 있음을 시사한다.
4. 임베딩 모델 선정 가이드
텍스트 임베딩 모델을 비교할 때는 보통 MTEB(Massive Text Embedding Benchmark) 리더보드를 참고한다. MTEB는 분류(Classification), 클러스터링(Clustering), 쌍분류(PairClassification), 재순위(Reranking), 검색(Retrieval), 텍스트 의미적 유사도(STS, Semantic Textual Similarity), 요약(Summarization) 등 다양한 임베딩 작업에서 모델 성능을 평가하는 대규모 벤치마크이다. 이 리더보드를 통해 각 모델의 특성과 강점을 파악하고, 성능 순위를 확인할 수 있다.
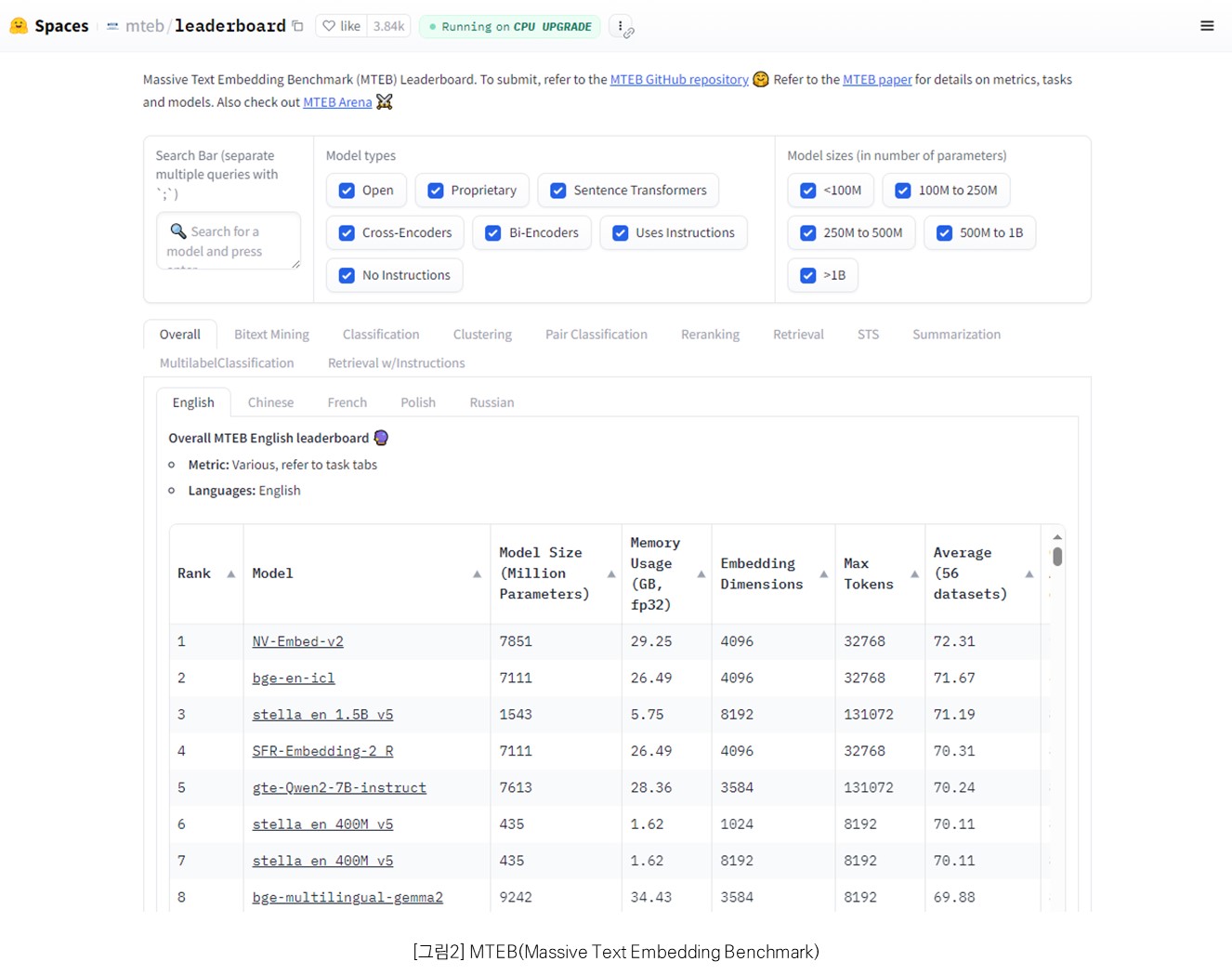
최근 임베딩 모델 순위를 보면, 디코더 기반 모델이 인코더 기반 모델보다 더 높은 순위를 차지하는 경우가 많다. 이는 디코더 기반 모델이 인코더 기반 모델 대비 대부분 더 높은 차원의 벡터 임베딩을 지원하기 때문이다. 그러나 고차원 임베딩은 변환/검색 시 더 많은 메모리와 연산량을 요구한다. 특히, 임베딩 모델을 유사도 검색에 활용할 것이라면 대부분의 벡터 데이터베이스(Vector Database)가 GPU가 아닌 CPU에 의존하고 있다는 점에 주목해야 한다. 생성된 벡터 임베딩은 정수형이 아닌 부동소수점 연산을 하는데 CPU는 부동소수점 연산이 상대적으로 GPU에 비해 취약하다. 따라서 대량의 데이터 처리 시 고차원의 벡터 임베딩을 사용할 경우, 검색 품질(quality)은 좋아질 수 있지만 검색 성능(performance)은 떨어질 수 있다. 만약, 프로젝트의 비용이나 환경 및 안정적인 운영을 고려한다면 고품질의 인코더 모델을 선택하는 것도 좋은 전략이 될 수 있다.
또한, 임베딩 모델을 선택할 때는 독점 모델과 오픈소스/오픈 가중치 모델도 함께 고려해야 한다. 독점 모델은 일반적으로 더 높은 품질을 제공하지만, API를 통해 외부 서버에서 제공되는 경우가 많아 데이터를 방화벽 밖으로 전송해야 할 수 있다. 이에 따라 보안이 중요한 환경에서는 독점 모델이 적합하지 않을 수 있다. 반면, on-premise 환경에서는 오픈소스 모델이나 오픈 가중치 모델을 사용하는 것이 적합하다. 추가적인 성능 개선이 필요하지 않다면 오픈 가중치 모델도 충분히 좋은 선택이 될 수 있지만 특정 용도로 활용하기 위해 미세조정까지 고려하고 있다면, 오픈소스 모델을 선택하는 것이 더 유리하다.
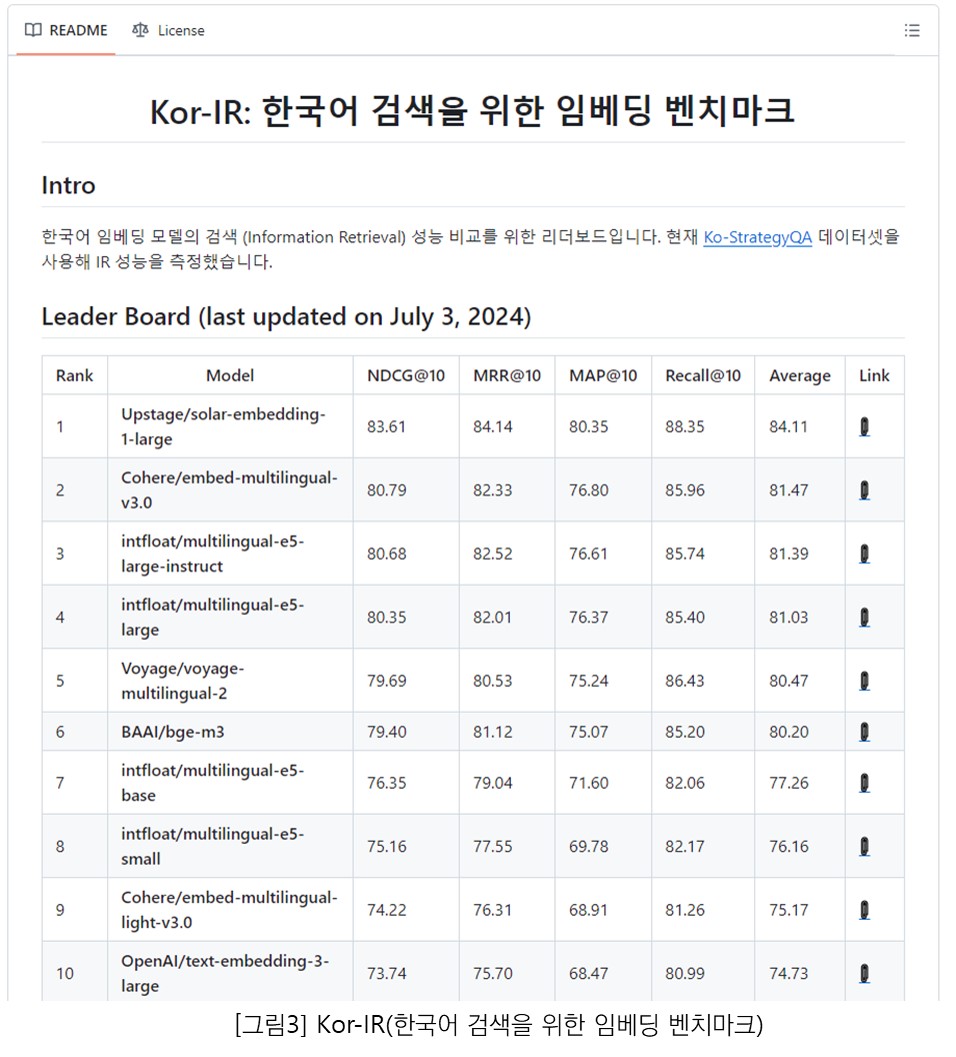
아쉽게도 2024년 하반기 기준으로, MTEB에서는 한국어 성능 평가를 제공하지 않고 있다. 한국어 임베딩 모델의 성능을 평가하려면 Kor-IR(https://github.com/Atipico1/Kor-IR) 같은 사설 리더보드를 활용하는 방법이 있다. 다만 이러한 리더보드는 비정기적으로 업데이트되기 때문에 최신 모델을 평가하는 데는 한계가 있을 수 있다. 만약 검증되지 않은 모델을 적용해야 한다면, 공인된 외국어 데이터 세트를 번역하거나, 자체적으로 데이터 세트를 정제한 후, 다양한 지표를 사용해 전문가와 함께 검증하는 과정이 필요하다.
에스코어는 삼성그룹사 임직원이 사용하는 그룹웨어의 RAG(검색엔진 증강) 프로젝트를 통해 생성형 AI 활용도를 높이고, 답변의 신뢰성을 강화한 경험을 가지고 있다. 또한, 에스코어는 아키텍처 설계, 데이터 마이그레이션, 구축 및 기술 지원 등 프로젝트의 전 단계에서 협력할 수 있는 각 분야의 오픈소스 소프트웨어 전문가를 보유하고 있다. 한국어를 고려한 최적의 벡터 임베딩 모델 선정은 물론, 최신 오픈소스 기술 기반으로 생성형 AI 서비스 구축을 고려하고 있다면, 에스코어의 전문가와의 협업은 탁월한 선택이 될 것이다.
마치며
현재 인공지능 분야에서는 생성형 모델이 주목을 받고 있으나, 임베딩 모델 역시 다양한 영역에서 중요한 역할을 수행하고 있다. 특히 RAG(Retrieval-Augmented Generation, 검색 증강 생성) 시스템과 같은 생성형 AI 기반 서비스에서 임베딩 모델을 활용한 유사도 검색은 핵심적인 부분을 차지한다. 생성형 AI 기반 서비스를 개발하는 경우, 프로젝트의 특성과 요구 사항에 적합한 임베딩 모델을 선정하고 효과적으로 활용하는 것이 중요하며, 이를 통해 시스템의 답변 정확도와 신뢰성을 향상할 수 있다. 결론적으로, 생성형 AI 기술의 발전과 함께 임베딩 모델의 중요성 역시 간과해서는 안 된다. 두 기술의 균형 있는 발전과 통합적 활용이 향후 AI 서비스의 질적 향상을 이끌어낼 것이다. 또한 개발자와 연구자들은 생성형 모델 뿐만 아니라 임베딩 모델에도 지속적인 관심을 가지고, 이를 효과적으로 조합하여 더욱 강력하고 신뢰할 수 있는 AI 시스템을 구축해 나가야 할 것이다.
# References
Elastic. What is vector search? Elastic, n.d. Web. 4 Oct. 2024. https://www.elastic.co/kr/what-is/vector-search.
"What is embeddings in machine learning?" Amazon Web Services, n.d. Web. 4 Oct. 2024. https://aws.amazon.com/ko/what-is/embeddings-in-machine-learning/.
Mikolov, Tomas, Kai Chen, Greg Corrado, and Jeff Dean. "Efficient estimation of word representations in vector space." arXiv preprint arXiv:1301.3781 (2013).
Vaswani, Ashish, et al. "Attention is all you need." In Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017.
"ChatGPT Whitepaper." Samsung SDS. Accessed 4 Oct. 2024. https://www.samsungsds.com/kr/insights/chatgpt_whitepaper1.html.
"Open Source vs. Open Weights vs. Restricted Weights." Prompt Engineering. Accessed 4 Oct. 2024. https://promptengineering.org/llm-open-source-vs-open-weights-vs-restricted-weights/.
"Nomic Embed Text V1." Nomic. Accessed 8 Oct. 2024. https://www.nomic.ai/blog/posts/nomic-embed-text-v1.
OpenAI. "Embeddings Guide." OpenAI Documentation. Available at: https://platform.openai.com/docs/guides/embeddings
Wang, Shuang, et al. "Text embeddings by weakly-supervised contrastive pre-training (E5)." arXiv preprint arXiv:2212.03533 (2022).
Wang, Shuang, et al. "Improving text embeddings with large language models (E5-Mistral-7B)." arXiv preprint arXiv:2401.00368 (2024).
Wang, Shuang, et al. "Multilingual E5 text embeddings: A technical report." arXiv preprint arXiv:2402.05672 (2024).
"MTEB Leaderboard." Hugging Face. Accessed 4 Oct. 2024. https://huggingface.co/spaces/mteb/leaderboard.
"Kor-IR." GitHub. Accessed 4 Oct. 2024. https://github.com/Atipico1/Kor-

김원섭 프로
소프트웨어사업부 OSS사업팀
검색엔진을 활용하여 더 나은 서비스를 제공하는 것에 관심이 많으며, 다양한 오픈소스 커뮤니티에 기여 활동(Contribution)을 하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.