들어가며
일반적으로 기업에서 활용중인 데이터 분석 시스템은 1세대 시절에 Data Warehouse(이하 DW) 아키텍처가 주류로 활용되다가 데이터의 유형이 다양해 지고 양도 점차 많아 지면서 2세대 Data Lake(이하 DL) 아키텍처가 더 많이 활용되는 추세다. DW는 주로 분석 리포트 및 BI 도구를 지원하고 DL은 데이터 사이언스 환경도 지원한다.
전통적 빅데이터 처리 플랫폼은 아래의 리포트를 참고하기 바란다.
바로가기 : 빅데이터에 대한 의미 및 전통적인 데이터 처리 구조에 대한 이해
대부분의 기업 및 조직들은 데이터를 기반으로 비즈니스 추진을 기대하며 중앙의 Data Lake 와 데이터 팀에 투자한다. 그러나 초기에 몇 번의 빠른 성공을 거든 후 폭발적으로 늘어나고 있는 대량 데이터를 처리하기에는 중앙의 데이터 팀이 종종 병목 현상이 있음을 알게 된다.
본 리포트에서는 위와 같은 문제의 대응 방안으로 최근 3년전부터 대두된 데이터 관리 아키텍처의 논리적 디자인을 정리한 Data Mesh에 대해 이야기 하겠다.
Data Mesh로 데이터 MSA化
서버 어플리케이션 디자인 패턴에는 “서비스 단위 모듈화” 혹은 ‘MSA(Micro-Services-Architecture)’가 있다. 이와 유사하게 데이터 관리 구조 패턴에는 Data Mesh가 있다. Data Mesh는 데이터 관리의 탈 중앙화로 전문적 도메인 지식을 업무 도메인 팀으로 이관하여 의사 결정을 신속하게 할 수 있도록 도와주는 데이터 관리 패러다임이다. Data Mesh라는 용어는 최초로 ‘2019년에 미국의 ThoughtWork社의 수석 컨설턴트, 자막데가니(Zhamak Dehghani)에 의해 정의되었다. 자막데가니는 이 용어를 도입한 이후, 2020년 초기부터 한 해를 들여 이 용어의 원리와 논리적 아키텍처에 대해 상세히 설명하였고, 그렇게 Data Mesh는 2021년부터 현재까지 데이터 업계에 “큰 관심사”가 되었으며, ‘Zalando’, ‘Netflix’ , ‘Intuit’, ‘VistaPrint’ 등의 회사에 의해 최초 구현 되었다.
Data Mesh의 필요성
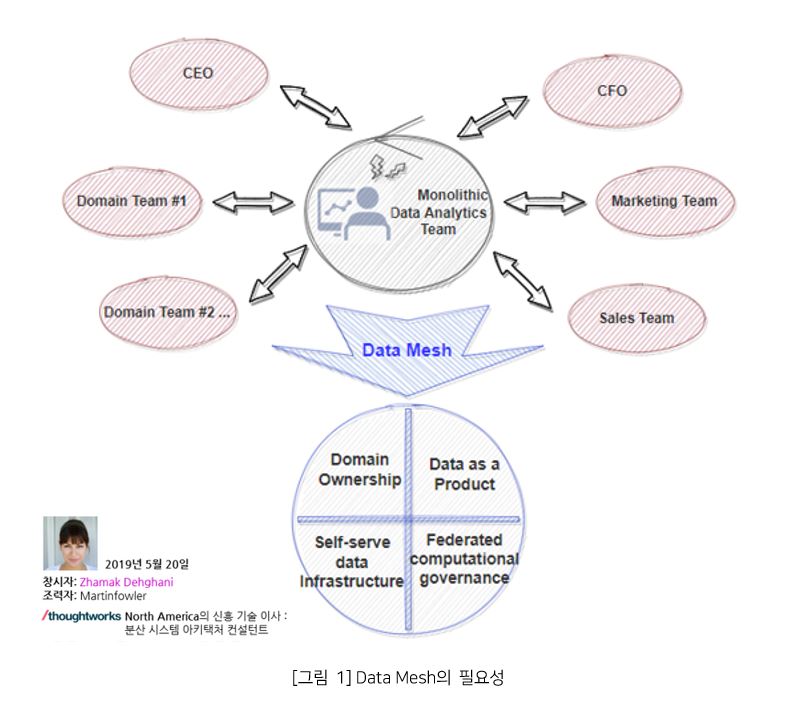
위 [그림 1]를 보면 중앙(Monolithic)의 데이터 분석팀이 기업의 경영진과 여러 부서의 갖가지 요구사항들에 대해 압박과 스트레스를 받아가며 힘들게 일하는 모습이 보인다. 현실적으로 단일 분석팀이 경영진과 제품 오너의 모든 분석 질문에 대해 신속한 답변을 내는 것은 어렵다. 이유는 비즈니스 인사이트와 관련된 모든 질문에 대해 답하기 위해서는 도메인 지식은 매우 중요하기 때문이다. 그럼에도 불구하고 적시에 데이터 기반으로 결정을 내리는 것은 기업 비즈니스의 경쟁력을 높이기 위한 매우 중요한 요소이기도 하다. 그럼, 도대체 Data Mesh가 무엇이고 어떤 가치를 제공할까? Data Mesh는 지난 10년간 발전해온 데이터 볼륨의 규모와 데이터 처리 컴퓨팅 해결에 대한 기술 발전을 넘어서 데이터 환경에 대한 변화, 데이터 소스의 확산, 데이터 사용 사례 및 사용자의 다양성과 같은 논리적 관점의 다른 차원의 문제를 해결하기 위한 디자인 패턴이다.
Data Mesh의 핵심원칙
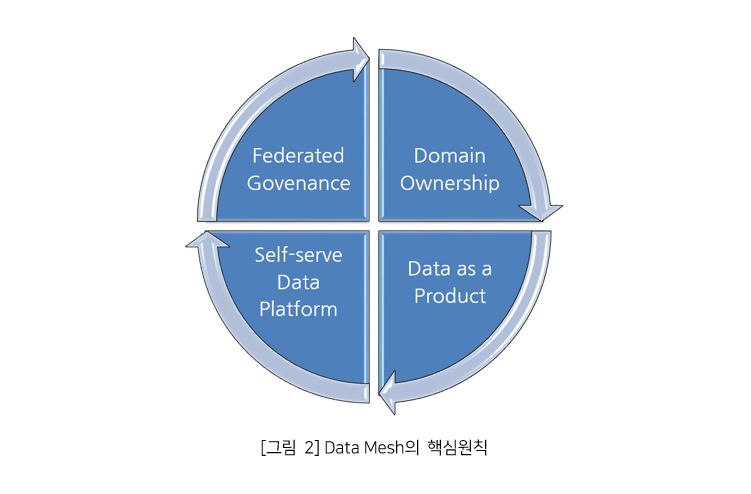
여기서는 핵심 원칙에 대해 간략히 설명하고 Data Mesh의 논리적 디자인 설명 시 자세히 소개하겠다.
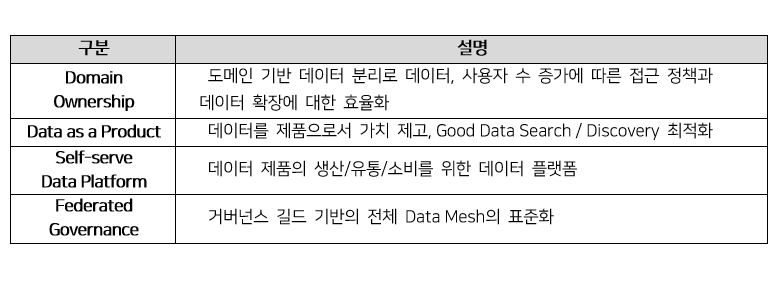 도메인 소유권(DomainOwnership)은 Bounded Context 원칙 기준으로 데이터의 분석, 운영, 책임, 소유권을 각 도메인 전문 팀에 이관 및 분산하여 도메인 데이터의 탈 중앙화를 실현하는 것이다.
도메인 소유권(DomainOwnership)은 Bounded Context 원칙 기준으로 데이터의 분석, 운영, 책임, 소유권을 각 도메인 전문 팀에 이관 및 분산하여 도메인 데이터의 탈 중앙화를 실현하는 것이다.
제품으로서의 데이터(Data as a Product)는 빅데이터의 5V 특성 중 가장 중요한 Value와 관련성이 있다. 데이터를 단순히 내부 소비로만 취급하는 것이 아니라 타 도메인 영역의 요구에 대해서도 만족시킬 수 있도록 제품 수준의 가치를 제공하는 것이다. 각 도메인 팀은 오류가 없는 고품질 데이터를 다른 데이터 소비자들이 접근 가능한 인터페이스를 퍼플리싱 한다(SQL, API 등). 데이터 제품화는 데이터 관리의 탈 중앙화에 따른 데이터 사일로 이슈와 품질 문제를 해결해주고 도메인 팀간에 상호운용성을 보장해준다. 이렇듯 하나의 데이터 제품은 Data Mesh의 Echo 체계 환경에서 제품 생산자(Product Owner)와 소비자간의 유통 과정에서 제품의 신뢰성을 보장받고 지속적으로 자가 발전하게 된다.
셀프 서비스 데이터 플랫폼(Self-serve Data Platform)은 플랫폼을 기반으로 데이터 제품의 Echo 생태계(생산, 소비, 관리, 재생산 등)를 구축하는 것으로 보면 된다. 이 원칙을 위해서는 기업내 “데이터 플랫폼” 전담 팀(혹은 외산 상용 솔루션 도입)이 필요하다. 플랫폼 팀은 각 도메인 팀들이 독립적으로 데이터 제품을 관리 및 책임질 수 있게 도구 및 시스템을 제공해야 한다. 각 도메인 팀은 이 플랫폼을 기반으로 데이터 제품을 스스로 셀프-호스팅, 실행, 관리까지 가능하게 된다. 더 나아가 도메인 별 데이터 제품은 각 도메인 팀간에 상호 운용까지 확대될 수 있다.
연합 거버넌스(Federated Governance)는 플랫폼을 기반으로 Data Mesh에 참여한 모든 구성원 들이 Data Mesh의 생태계를 운영하기 위한 체계이다. 거버넌스를 통해 규칙과 규정을 플랫폼에 지속적으로 재 반영하게 된다.
Data Mesh의 논리적 디자인
Data Mesh 아키텍처는 각 도메인 팀이 스스로 타 도메인 팀의 데이터 제품과 크로스 분석이 가능한 분산형 구조로 정의 된다. Data Mesh의 논리적 아키텍처의 구성요소는 아래 [그림 3]과 같다.
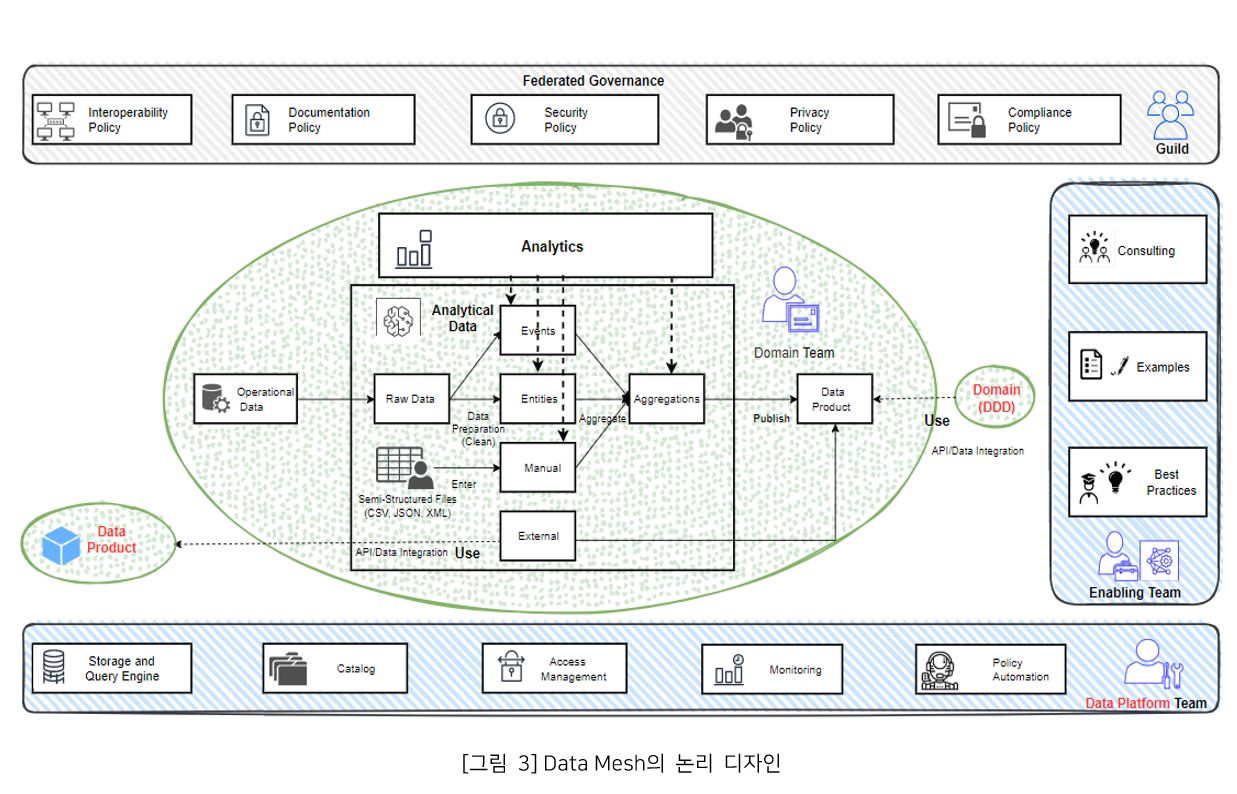
연합 거버넌스(Federated Governance)는 각 도메인 팀, 플랫폼 전담 팀, 분석 지원 팀의 대표자로 구성된 길드 체제로 운영이 된다. 각 팀 대표자의 주도하에 Data Mesh에 참여한 각각의 모든 팀원들은 표준 정책에 동의하고 정책을 준수하게 된다. 길드 구성원이 정한 표준 정책으로 기업 내 모든 데이터 제품들이 일관된 방식으로 사용 가능하게 된다. 예를 들어 도메인 팀이 소유한 데이터 제품의 엑세스 방법을 AWS S3의 버킷에 CSV 파일이나 JSON 파일에 명시하는 방식으로 정의할 수 있다. 이러한 정책으로 이질적인 데이터 제품들의 상호 운용성이 보장된다. 그리고, 퍼블리싱된 데이터 제품의 이름, 위치 정보 등을 AWS의 Tag 기반 자원 관리 방식처럼 메타데이터를 등록 및 조회한다면 검색(Data Discovery)에 대한 효율성을 높일 수 있다.
분석 데이터(Analytical Data)는 도메인 팀에서 운영중인 서비스의 원시 데이터로부터 수집된다. 도메인 중심 설계 원칙에 따라 엔터티 및 집합체(Data Set)로 변경 불가한 도메인 이벤트로 정의된다. 종종 반정형 포맷의 파일의 경우는 데이터 엔지니어가 매뉴얼 방식으로 직접 업로드를 하기도 한다(예: 메일의 첨부 파일). 일반적으로 원시 데이터는 비즈니스 개체 단위의 엔터티(Entity) 데이터와 작은 단위의 이벤트 스트리밍 로그 데이터를 포함한다. 엔터티는 시간의 흐름에 따라 변화되는 데이터 이다. RDBMS의 원시 데이터는 배치 방식의 ETL 도구와 실시간 동기화 방식의 CDC 도구를 통해 수집된다. 이 과정에서 중복된 데이터의 제거, 정규화 등 구조화 및 보정 과정을 통해 자연스레 분석을 위한 데이터로 변환된다. 스트리밍성 데이터의 수집 방법은 Kafka 기반의 다양한 오픈소스가 있다.
그 예로 비동기 채널 방식의 자바 프로세스로 구현된 Apache Flume은 분산 환경에서 로그를 수집하여 Data Lake로 모아주는 오픈소스다. Flume은 다양한 하둡 에코 시스템(HDFS, HBase, Hive 등)과 IPC(Avro, Thrift, Kafka Streams)기반 전송 인터페이스와 같은 Sink(타겟 저장소)로 복제할 수 있다. 또한, Kafka Connector는 Plug-in 방식으로 다양한 유형의 Sink로 데이터를 통합할 수 있는데, 특히, 오픈소스 Debezium을 활용한다면 CDC 기술의 데이터 트랜잭션 로그 캡쳐 방식을 기반으로 Source 저장소에서 데이터를 실시간으로 추출, Kafka Cluster를 통해 대용량 이벤트 데이터에 대한 전달을 보장하고, Sink 저장소로 데이터가 안전하게 복제되어 원격지간 데이터를 실시간 동기화 할 수 있게 된다. 이러한 과정을 통해 얻어진 분석 데이터 모델들은 하나의 도메인 데이터로 합쳐져(Aggregate) 데이터 제품으로 발행 (Publishing)될 수 있다. 하나의 데이터 제품은 다른 도메인 팀이 발행한 데이터 제품을 포함하여 만들어질 수 있고, 다른 도메인 팀 소유의 데이터 제품의 부속으로 소비될 수 있다.
데이터 제품은 일반적으로 API와 유사하게 다른 도메인에서 액세스할 수 있는 게시된 데이터 세트이다. 이 제품은 다양한 저장소와 포맷으로 제공될 수 있다. DW에서는 RDBMS의 Table 혹은 Virtual Table(View, Temporary Table) 형태로 만들어질 수 있고 DL의 경우는 NoSQL의 Table 혹은, CSV 파일 유형으로 AWS S3의 Object로 저장될 수 있다. 이러한 데이터 제품은 제품의 소유권, 제품 책임자에 대한 연락처, 제품의 업데이트 빈도, 위치 URL, 데이터 모델 사양 등과 같은 메타데이터를 포함한다. 데이터 제품이 제공하는 기능적 원칙은 중복이 제거된 정보, 싱싱한 과일과 같은 신선함 (예를 들어 5분이내 데이터)을 제공해야 하고, 24시간 동안 지속 사용이 가능해야 한다. 하나의 데이터 제품은 타 도메인 팀의 요구사항을 충족해야 한다.
분석지원 팀(Enabling Team)은 기존의 중앙 분석팀이 그들의 분석 노-하우를 통해 각 도메인 팀이 분석 업무를 효율적으로 처리하기 위해 도와주는 분석 전문가 팀이다. 종종 특정 도메인 팀에 일정 기간 동안 파견 형식으로 지원을 나가는 경우도 있다.
이 팀의 초기 역할은 도메인 팀이 스스로 데이터 제품에 대한 통찰력을 얻기 위해 탐색, 처리, 집계, 분석 등과 같은 Analytics 관련 역량을 습득할 수 있도록 예시 와 모범 사례를 제공한다. 데이터에 대한 명확한 분석을 위해 시각화 도구를 활용한다면, 데이터의 추세, 명확한 성과 지표(KPI), 데이터에 대한 필터링 작업을 용이하게 할 수 있다. 데이터 시각화 (Data Visualization) 작업을 위해 비교적 자유도가 우수한 제품을 살펴보겠다.
태블로(Tableau)는 유료(Desktop)와 무료(Public) 버전이 있다. 유료 버전의 경우 40개 가량의 다양한 데이터 커넥터를 제공하지만 무료 버전은 기본 데이터베이스(JDBC), OData, 구글 스프레드시트를 제외하고 그 외 기능은 제약된다. 데이터는 반정형 파일(CSV 등)과 서버 데이터 커넥터로 업로드 할 수 있다. 업로드 완료 후 데이터를 연결하고, 손쉽게 그래프 컴포넌트들을 Drag&Drop하면 알아서 시각화 차트가 그려진다. 여러 개의 차트를 그리기 위해서는 시트를 추가하면 된다. 즉, 시트당 그래프 한 개로 그려진다. 태블로가 제공하는 기능을 익히기 위해서는 많은 시간이 필요로 하지만 다양한 시각화 차트를 맛볼 수 있어서 최근 BI 시장에서 많은 사랑을 받고 있다. 이러한 BI 툴과 더불어 AI/ML 기반의 고급 분석 툴을 활용하면 분석 방법의 특화, 미래예측에 많은 도움이 된다. 이 또한 기술적 역량이 필요로 하는데, 분석지원 팀이 Helper가 되는 것이 방법이 된다.
데이터 플랫폼 팀(Data Platform Team)은 Data Mesh의 거버넌스 원칙에 따라 각 도메인 팀들이 데이터 제품을 생산, 유통, 소비가 가능하도록 기술적 환경과 도구를 제공하는 팀이다. 각 도메인 팀은 데이터 플랫폼을 활용하여 데이터 제품을 독립적으로 만들고 관리 및 책임질 수 있게 된다. 플랫폼이 제공하는 주요 기능은 다음과 같다.
1) Data Catalog는 데이터 사일로를 방지하고 도메인간 합쳐진 인사이트(Cross Domain)를 발견하는데 도움을 준다. 즉, 숨겨지고 버려진 데이터를 최소화하기 위해 타 도메인 팀이 양질의 데이터를 효율적으로 찾을 수 있게 기능을 제공한다.
2) 쿼리 엔진(Query Engine)은 플랫폼의 가장 중요한 핵심 기능이다. 데이터가 분산환경으로 퍼져 있고 심지어 이기종 저장소일 경우 어떻게 데이터를 통합하고 처리할지에 대한 기술적 최적화 이론이다. 힌트는 Data Federation, EII(Enterprise Information Integration) 기술을 기반으로 발전된 데이터 가상화 기술을 고려해 볼 수 있다. 간략히 설명하면 데이터를 물리적으로 복제하거나 통합하는 방식이 아닌, 원본데이터는 DL 혹은 DW의 위치에 유지한 상태로 원격으로 접근하는 방식이다. 이때 이기종 저장소들로부터 얻어진 가상의 결과를 쿼리 최적화 로직을 통해 최종 결과를 빠르게 출력하는 기술을 의미한다.
3) 접근 관리(Access Management)는 거버넌스의 표준 정책에 따라 플랫폼에 접근하는 사용자들에 대한 인증 및 인가를 관리하는 기능으로서 데이터 제품별 Create/Read/Update/Delete에 대한 제어로 생각하면 된다. AWS 환경을 예로 든다면 권한 관리를 위한 IAM(Identity Access Management) 기능과 Tag 기반으로 자원을 관리하는 Resource Groups 기능을 접목하여 자원(데이터 제품)에 대한 접근 권한 정책을 정의하는 것도 방법 중에 하나가 될 수 있다.
4) 모니터링(Monitoring)은 데이터 제품에 관련된 전체 현황, 데이터 플랫폼의 중요 서비스들에 대한 실행 현황 및 서비스가 설치된 서버들에 대한 시스템 성능, 보안 위반 및 컴플라이언스에 대한 감사 정보를 실시간으로 파악하기 위한 정보를 제공한다. 예를 들어 구성원 및 조직 별로 데이터 제품에 대한 엑세스 현황을 파악하기 위한 로깅 및 오딧(Audit) 기능이 그 예다.
5) 정책 자동화(Policy Automation)는 길드에서 수립한 거버넌스 정책의 위반 여부를 일일이 확인하는 불편을 덜어주기 위해 플랫폼을 통해 설정된 정책을 자동 반영해주는 기능이다.
중앙 데이터 저장소를 ‘DDD’ 경계로 나눠 데이터를 제품화 하기
DDD(Domain Driven Design)는 에릭 에반즈(Eric Evans)가 운영중인 모놀리식(Monolithic) 서비스를 MSA 구조로 분리하고, 모듈화하는 관점에서 최초로 주장한 디자인 패턴이다. DDD는 도메인 독립적으로 지식, 행동/활동, 법률을 의미론적으로 결합하고 그에 따른 의존성을 함께 모으는 방법론이다. 결합을 위한 수집 활동은 도메인에 대한 경계로 나누는 과정을 통해 가능해진다. DDD의 설계 전략에 대한 모호성을 구체화하고 의존관계를 식별할 수 있게 하여 DDD의 가속화 방법론을 고안해낸 사람은 이탈리아의 DDD 컨설턴트인 알베르토 브란돌리니(Alberto Brandolini)다. 알베르토는 도메인 이벤트를 중심으로 비즈니스의 모든 Stakeholder(고객, 도메인전문가, 설계자, 개발자, 테스터 등)들이 모여 워크샵 형태로 브레인 스토밍을 하는 방식이라 하여 이벤트 스토밍(Event Storming)이라 명명하였다. 이러한 애플리케이션의 도메인 원칙을 데이터 도메인에 적용한 것이 Data Mesh 설계 패턴이다. 그럼, Data Warehouse와 Data Lake에 저장된 대규모 데이터를 효율적으로 그룹핑할 수 있을까?
자! 이제부터 Data Mesh의 관점에서 바라본 DDD의 핵심 원칙을 상위 수준(High Level)으로 알아보자.
아래는 Data Mesh의 데이터 도메인에 DDD 원칙을 적용한 용어이다.
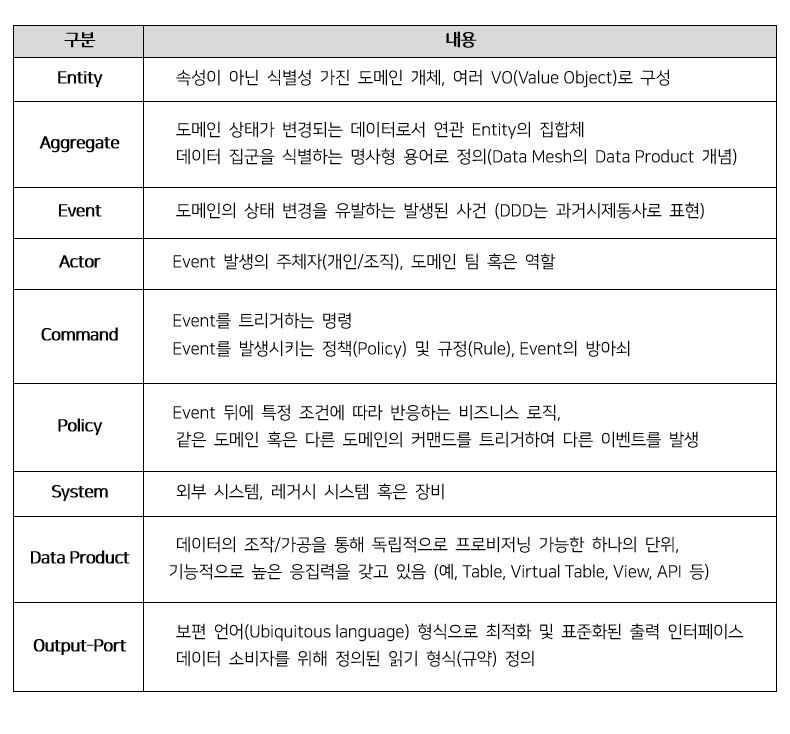
DDD에서 이벤트 스토밍과 동일하게 Data Mesh에서도 도메인 데이터 별 경계를 구분할 때 열린 마음으로 적극적인 참여가 필요하다. 진행자(Facilitator)는 조력자 역할로 이 활동을 촉진한다.
아래 그림 5는 Event Storming을 통해 얻어진 도메인 별의 데이터 제품과 데이터 제품간의 관계에 대한 설명이다.
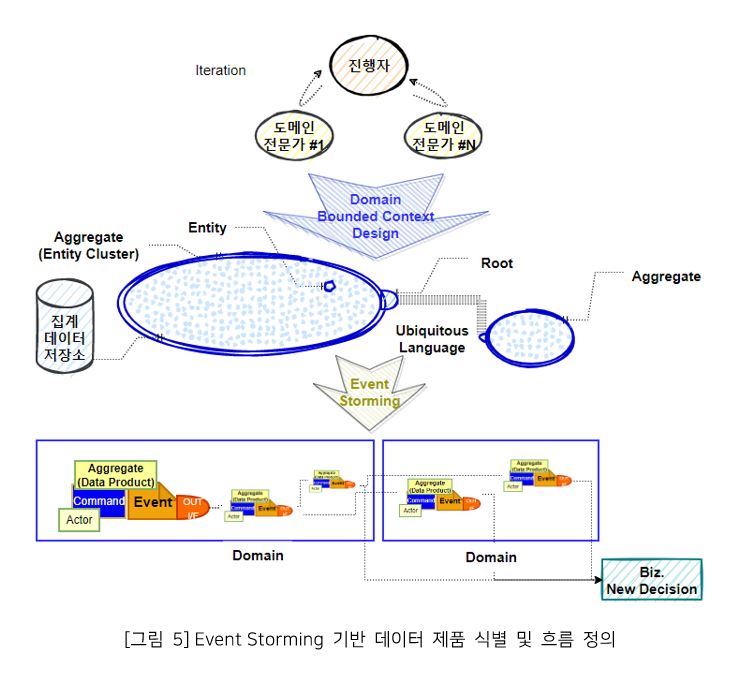
위 그림과 같이 하나의 Domain 조직 내에는 1개 이상의 데이터 제품을 생산 및 관리할 수 있다. 또한, 데이터 제품은 하나의 Domain 내부에서 쓰여질 수도 있고, 표준화된 인터페이스 규격(Output-Port)을 통해 다른 Domain으로 데이터를 전달할 수도 있다.
자! 아래의 가상 예시는 기업의 쇼핑몰에서 제품이 판매되는 흐름을 보여준다.

이 예시를 Data Mesh 생태계 흐름으로 비유해보면,
장신구 → 데이터 제품
고객 → 데이터를 소비하는 ‘도메인 팀’
배송 → 표준 Output-Port(API/SQL 등)
제품 판매 업체 → 제품의 ‘도메인 오너팀
이와 같이 도메인 팀 간에 데이터 제품의 유통(생산/소비) 흐름으로 이해할 수 있다. 즉, 도메인 팀이 생산한 제품은 다른 도메인 팀에게 제품으로서의 가치를 제공해 줄 수 있다.
이번에는 다른 시각으로 위의 가상 시나리오를 각 도메인의 데이터 제품을 연합된 분석(Cross Domain) 결과로 접목해 본다면?
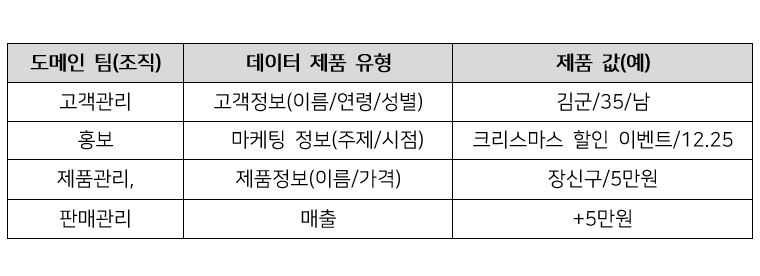
위 표에서 데이터 제품은 DDD의 Output-port를 통해 제공된 데이터 집합이라 가정하고, 각 제품별 소유 부서는 도메인 담당 팀으로 가정해보자.
Data Mesh 기반의 도메인 별 연결 관계(Cross Domain)로 바라본다면 특정 고객(35세, 남자, 김군)이 어떤 마케팅 행사(크리스마스 할인 이벤트, 12.25)를 통해 어떤 제품(5만원, 장신구)을 구매했다. 이를 통해 제품별 매출 분석(마케팅의 효과 여부, 선호 연령/성별, 최다 판매 제품 선별 등)을 할 수 있다.
이벤트 스토밍 워크샵을 통해 중앙의 대량 데이터들을 비즈니스 도메인 단위로 분리하는 과정은 힘든 여정이 될 수 있다. 워크샵의 효율적인 진행을 위해서는 도메인 데이터에 대한 조기 합리화, 최적화, 특히 성급하게 테이블 명을 정의 하는 행위는 피하는 것이 좋다. 반복적으로 제품을 위한 데이터를 모델링 하고 수집된 용어(데이터 모델)는 용어집(집계 저장소)에 보관한다. 워크샵의 최종 골은 Domain Bounded Context 원칙에 따라 쌓여 있는 데이터들에 대해 도메인 데이터를 그룹핑하여 결과물(Aggregate)을 얻는 것 이다. 이 결과물은 데이터 제품의 범위와 규모를 명확히 해준다. 데이터들에 대한 도메인 별 분리가 정리가 되었다면, 연합 거버넌스 체계의 표준 정책으로 제품이 등록되어 일관된 방식으로 제품 사용이 가능해 진다.
시사점
지금까지 빅데이터를 굿데이터로 활용할 수 있는 논리적 전략에 대해 살펴봤다. Data Mesh의 근원적 뿌리는 Self-Serve Platform이다. Self-Serve Platform의 기술적 방법론은 데이터 가상화 기술 혹은 DL과 DW의 장점만을 취한 데이터 Lakehouse라는 신 개념을 통해 가능하게 된다. Platform의 튼튼한 뿌리를 통해 적합한 영양분을 공급하여야만 가치 있는 열매(Good Data Product)를 얻을 수 있게 된다. Data Mesh는 기업이 보유한 데이터를 조직별 Domain 단위로 구분하여 데이터를 제품 수준으로 제공과 소비를 용이하게 해준다. 또한 부서(Domain)간 연결이 필요한 데이터를 제품으로서 제공 및 연결한다면 데이터에 대한 관리 효율화, 명확한 책임, Cross Domain Data에 대한 분석이 가능해진다.
그러나, Service Mesh 환경 구축을 위해 모놀리식에서 MSA로의 전환 시 고려해야 할 사항이 많고 쉽지 않은 일인 것처럼 Data Mesh 또한 여러 가지 사항들을 고려해야 한다.
첫째, Data Mesh 기반의 아키텍처도 기존에 사용하던 대형 Repository가 여전히 필요하다. 원천 데이터는 DDD를 기반으로 데이터 제품을 조립하기 위한 재료(Entity)이기 때문이다. Data Mesh는 기존에 보유한 데이터들의 관리 효율화를 위해 연합 거버넌스와 메타 데이터 기반의 추상화된 Self-Serve Platform으로 도메인 별 자율적 운영 체계를 제공한다. 만일, 기존의 데이터 관리 구조 환경이 이미 존재한 다면 빅뱅(Big bang) 방식이 아닌, 점진적인(Strangler Pattern)방식으로 관리 구조를 전환하는 것이 현실적이다. 하지만, 초기 구축 단계부터 디자인을 고려하는 것이 무엇보다 바람직하다.
둘째, 데이터 구조를 도입해야 한다면, 데이터의 특색, 비용 효율화 관점을 고려해야 한다. 만일, 기업의 데이터가 적은 규모라면 자체적인 구축도 고려해 볼 수 있다. 그러나, 대규모이면서 데이터 관리 측면의 IT 역량이 평이하다면 전환에 필요한 다양한 전략과 대책을 두루 갖춘 전문 기술 업체를 통해 기술적인 노하우 와 컨설팅을 받는 것이 유리할 수 있다.
Data Mesh의 목표는 1) 데이터 환경의 끊임없는 변화에 대한 대응, 2) 데이터 소스와 소비자의 확산에 대한 유연성, 3) 사용 사례에 필요한 변환 및 처리의 다양성, 4) 대규모 데이터 분석 및 역사적 사실로부터 가치를 얻기 위한 기반을 만드는 것이다. Data Mesh는 빅데이터에 대한 디자인 패러다임을 발전시키기 위한 아키텍처로서 디딤돌 역할을 하기에 충분한 도움이 될 것이다.
# References
- https://martinfowler.com/articles/data-mesh-principles.html
- https://www.agilelab.it/how-to-identify-data-products-welcome-data-product-flow/
- https://www.tableau.com/ko-kr/why-tableau

손병창 그룹장
소프트웨어사업부 플랫폼사업팀
CDC 기반의 프리미엄 데이터 동기화 및 대용량 분산 메시징 처리 엔진을 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.