휴먼 포즈 에스티메이션(Human pose estimation)
컴퓨터 비전(Computer Vision)은 컴퓨터를 사용하여 인간의 시각적인 인식 능력을 구현하는 것을 목표로 합니다. 카메라로 촬영된 이미지나 영상을 분석하여 정보를 추출하는 것이 핵심이다 보니 객체의 위치와 방향을 탐지하는 것은 컴퓨터 비전에서 자주 등장하는 문제입니다.
이 중 사람이 취한 자세를 인식하는 기술을 “휴먼 포즈 에스티메이션(Human pose estimation)”이라고 합니다. 말 그대로 사진이나 영상 속에서 사람의 신체 관절이 어떻게 구성되어 있는지 위치를 추정하는 문제로 볼 수 있습니다. 그런데 사진 속에 담긴 사람의 모습은 모든 관절이 보이는 것은 아닙니다. 같은 자세라도 촬영된 방향에 따라 다르고, 때로는 다른 물체에 가려져 있기도 하며, 다양한 옷을 입고 있기도 합니다. 빛의 세기나 강도에 따라서도 추정하기 어려워 질 수 있습니다. 그래서 전체적인 추론(holistic reasoning)이 필요합니다. 이와 같이 휴먼 포즈 에스티메이션 기술은 컴퓨터 비전에서 오랫동안 다루어져 왔음에도 불구하고 여전히 어려운 분야에 속합니다.
전통적인 자세 인식 방법은 사람에게 센서와 같은 다양한 장비를 부착하는 것입니다. 움직임을 실시간으로 정교하게 파악할 수 있지만 높은 비용이 들어가기도 하고 실생활에서 항상 장비를 착용하는 것이 아니어서 연구실 또는 한정된 영역에서만 가능한 방법입니다. 그래서 몸에 부착하는 장비 없이, 사진에서 자세를 추정하는 휴먼 포즈 에스티메이션 연구가 진행되었습니다. 자세를 추정하기 위해서는 사진에서 인체의 윤곽이나 특정 신체부위를 추론할만한 외곽선 등의 특징을 추출해야 합니다. 이 특징의 패턴을 사람이 직접 분석하고 응용하여 신체 부위를 예측할 수 있게 되었고 효율성과 정확성이 날로 높아지고 있습니다.
최근 딥러닝(Deep Learning)은 컴퓨터 비전의 여러 분야에서 눈부신 성능 향상을 보이며 휴먼 포즈 에스티메이션 연구 패러다임을 바꾸고 있습니다. 딥러닝은 다층 인공신경망을 이용하며, 유용한 특징들을 데이터로부터 직접 학습하는 방식을 취합니다. 이러한 학습 기반의 방법은 사람이 미처 인지하지 못하는 유용한 특징들을 데이터를 통해 직접 찾아낼 수 있다는 장점이 있습니다. 휴먼 포즈 에스티메이션 분야에서도 딥러닝을 활용한 연구가 활발히 진행 중이고 문제 해결에 큰 성과를 거두고 있습니다. 자세 추정이 점점 정확해지면서 그 응용분야도 자세 교정, 행동 인식, 이상 행동 감지, 안전 예방 시스템, 증강현실 등으로 확대되고 있습니다. 최근에는 2차원 자세를 넘어서 3차원 자세 추출에서도 많은 연구가 진행 중입니다.
다양한 연구 결과들 중에 성능 향상과 더불어 소스를 공개해 많은 연구의 기반이 되어 준 오픈소스 프로젝트가 있습니다. 이 프로젝트를 살펴보면서 딥러닝 기반의 휴먼 포즈 에스티메이션에 대한 이해를 돕고, 이를 응용하면 무엇을 더 할 수 있을지 영감을 얻는 기회가 되었으면 합니다.
오픈포즈(OpenPose)
오픈포즈(OpenPose)는 세계 최대 ‘컴퓨터 비전 및 패턴 인식’ 컨퍼런스인 CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 2017에서 발표된 프로젝트로 미국 카네기멜론대학교에서 개발하였습니다. 딥러닝의 합성곱 신경망(Convolutional Neural Network, CNN)을 기반으로 하며, 사진에서 실시간으로 여러 사람들의 몸, 손, 그리고 얼굴의 특장점을 추출할 수 있는 라이브러리입니다. 아래 사진은 오픈포즈의 저자들로 이를 이용해 인체의 자세를 추정한 결과입니다.

이 프로젝트의 특징은 여러 사람의 자세를 빠르게 찾을 수 있다는 것입니다. 오픈포즈가 발표되기 전에는 여러 사람의 자세를 추정하기 위해 사진에서 각각의 사람을 검출하고 검출된 사람에 대해 자세를 찾도록 반복 수행하는 탑-다운(Top-Down, 하향식) 방식을 주로 사용했습니다. 오픈포즈는 바텀-업(Bottom-up, 상향식) 방식으로 반복적인 처리 없이 성능을 향상시켰습니다.
바텀-업 방식은 모든 사람의 관절을 추정하고, 각 관절의 위치를 이은 다음, 각각에 해당하는 사람의 관절 위치로 재생성 하는 방식입니다. 대게 바텀-업 방식은 관절이 어느 사람에게 속하는가의 문제로 정확도가 떨어지는 상황이었습니다. 오픈포즈는 이를 보완하기 위해서 신체 부위가 어느 사람에게 속하는지 유추할 수 있는 특징(Part Affinity Fields)을 이용하여 접근했습니다.
주요 기능
오픈포즈의 주요 기능은 사진이나 동영상 또는 카메라 입력을 통해서 여러 사람의 신체 부위 특징점의 위치를 실시간(초당 약 22프레임 – Nvidia GTX 1080 Ti 기준)으로 추적해 주는 것입니다. 여기서의 특징점은 어깨, 손목 등 몸의 관절뿐만 아니라 손과 얼굴도 포함됩니다. 추적하는 특징점의 목록은 아래 [그림 2]와 같습니다.

그러면 어떠한 방식으로 오픈포즈가 인체의 특징점을 추적할 수 있는지 딥러닝 네트워크의 구조를 살펴보도록 하겠습니다.
딥러닝 네트워크 구조
오픈포즈의 네트워크 구조는 아래 그림과 같습니다.
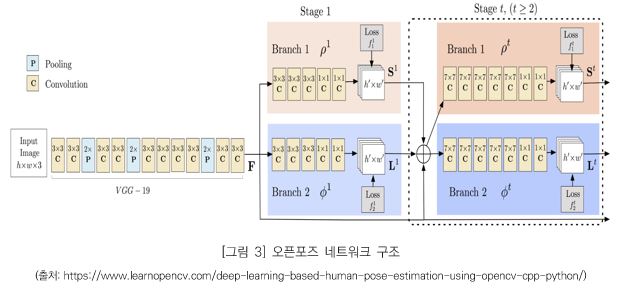
네트워크의 입력은 높이(h) x 폭(w) 크기의 컬러 이미지이고 VGG-19 네트워크의 일부를 통과하게 됩니다. VGG 네트워크는 옥스포드대학의 Visual Geometry Group에서 개발했습니다. 세계 최대 이미지 인식 경연대회인 ILSVRC(ImageNet Large Scale Visual Recognition Competition) 2014년 행사에서 GoogleNet과 함께 주목을 받으며 근소한 차이로 2위를 차지했지만, 구조가 간단하여 이해하기 쉽고 변형을 시켜가면서 테스트하기 용이한 장점이 있습니다.
이미지가 VGG-19 네트워크의 입력으로 들어가면, CNN의 Convolution layer(C)와 Pooling layer(P)를 거쳐서 특징맵(F)을 생성하게 됩니다. 특징맵(F)은 처음에는 큰 의미 없는 내용이 담겨 있지만 그 내용을 학습 데이터와 비교하며 차이점을 점점 줄여나가는 방향으로 최적화를 하면 학습 데이터에 맞는 특징을 갖게 될 것입니다. 그리고 이 특징맵(F)은 Stage1의 입력으로 들어갑니다.
Stage1은 2개의 브랜치로 나누어 집니다. 첫 번째 브랜치의 CNN(p1)은 모든 사람의 관절 위치를 결정하는 Confidence map(S)을 생성합니다. Confidence map은 특정 신체부위가 위치할 가능성에 따라 높은 값(최저 0 ~ 최고 1)을 갖는 흑백 이미지라고 할 수 있습니다. 관절이 위치한 픽셀을 중심(중심 값은 1.0)으로 퍼지면서 값이 감소하는 heatmap을 만듭니다. 예를 들어 아래 그림은 왼쪽 어깨에 대한 Confidence map과 실제 데이터를 겹쳐서 표현한 이미지입니다. 왼쪽 어깨에 해당하는 부분이 높은 값을 갖는 것을 보실 수 있습니다. 이 Confidence map을 학습 시켜서 사진으로부터 각 관절의 위치를 추정할 수 있습니다.

두 번째 브랜치의 CNN(ф)에서는 Part affinity fields(PAFs)를 예측하는데, PAFs(L)는 한 파트에서 다른 파트로 이어지는 방향(position and orientation)을 인코딩한 2D 벡터로 인체 부위 사이의 연관 정도를 나타냅니다. 이 정보는 관절이 연결된 정보를 담고 있고 누구의 것인가를 파악하는데 사용됩니다. 예를 들어 아래 [그림 5]는 왼쪽 어깨와 목의 Part affinity입니다. 같은 사람의 인체 부위(목, 어깨)가 크게 연관되어 있는 것을 볼 수 있습니다.

이후 Stage2부터는 Stage1의 출력인 Confidence map(S)과 PAFs(L), VGG network의 출력인 특징맵(F)을 조합해서 CNN의 입력으로 사용합니다. 네트워크가 깊어질수록 앞에 위치한 layer는 학습의 영향이 줄어들기 때문에 좀 더 나은 결과를 얻기 위해 매 Stage마다 특징맵(F)을 사용합니다. 네트워크의 각 Stage에서는 예측한 수치와 실제 훈련 데이터에 있는 정답과 비교를 통해 오차 값을 구하고 이를 최소화 하는 방향으로 네트워크를 학습시킵니다.
결과
아래 [그림 6]은 오픈포즈를 이용해 여러 사람의 자세를 추출한 결과입니다. 많은 사람들 속에서도 각자의 관절을 잘 추출하고 있습니다.

그러나 예외적인 경우도 발생합니다. [그림 7]과 같이 학습량이 부족하거나 학습되지 않았던 희귀한 자세, 몸의 일부가 보이지 않는 경우, 여러 사람이 겹치는 경우 등은 아직 해결하기 어렵고, 실제 사람이 아니지만 사람과 비슷한 형태를 지니면 자세를 추출하는 것도 보실 수 있습니다.

마치며
사람의 몸에 장비를 장착하지 않고 사진이나 영상으로 사람의 자세를 추출할 수 있는 오픈포즈에 대해서 살펴보았습니다. 휴먼 포즈 에스티메이션 분야는 딥러닝의 발전, 특히 CNN 기반의 접근 방식을 사용해 뛰어난 성과를 거두고 있습니다. 이를 실생활에 응용하면 다양한 분야에서 생산성을 향상시킬 수 있을 거라 생각됩니다. 최근에는 3D 자세 연구나 행동 인식 분야에서도 활발히 연구가 진행 중입니다. 저희 에스코어도 작업자의 근골격계 질환 예방에 활용하기 위한 3D 자세 추출과 자세 변화에 따른 행동 인식을 연구 중에 있습니다. 이외에도 더 살펴 볼 만한 휴먼 포즈 에스티메이션 연구들을 소개해 드리며 마치겠습니다. 관심 있으신 분들께 도움이 되셨으면 합니다.
– Stacked Hourglass Networks for Human Pose Estimation https://arxiv.org/pdf/1603.06937.pdf
– DensePose: Dense Human Pose Estimation In The Wild https://arxiv.org/pdf/1802.00434.pdf
– Holopose: Holistic 3D Human Reconstruction In-The-Wild http://openaccess.thecvf.com/content_CVPR_2019/papers/Guler_HoloPose_Holistic_3D_Human_Reconstruction_In-The-Wild_CVPR_2019_paper.pdf
송철호 프로
에스코어㈜ 소프트웨어사업부 미디어어플랫폼그룹
에스코어 미디어플랫폼그룹에서 컴퓨터 비전, 데이터 분석 및 인공지능 R&D를 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.