엘라스틱서치(Elasticsearch)는 엘라스틱(Elastic)社가 아파치 루씬(Apache Lucene)을 기반으로 개발· 공급하는 오픈소스 검색엔진 솔루션이다. 루씬은 강력한 검색 기능을 탑재하고 있지만 라이브러리 형태로 제공되다 보니 실제 적용 시에는 많은 부분을 직접 개발해야 한다. 반면 엘라스틱서치는 루씬의 기능을 대부분 지원하면서 대용량 데이터 처리가 가능하고 설치와 구성이 용이하다.
2010년 공개 이후 엔터프라이즈 검색엔진의 대표 주자로 자리매김 하고 있는 엘라스틱서치는 검색 기능을 중심으로 다양한 솔루션이 결합하면서 엘라스틱 스택(Elastic Stack)이라는 통합 브랜드로 진화하고 있다. 엘라스틱 스택은 사용자가 서버로부터 데이터를 가져와서 실시간으로 검색·분석·모니터링 및 시각화 하는 오픈소스 소프트웨어 제품군이다. 분산형 검색엔진 엘라스틱서치, 다양한 플러그인을 이용하여 데이터를 수집하는 로그스태시(Logstash), 데이터 시각화 도구 키바나(Kibana) 및 경량 데이터 전송기 비츠(Beats)로 구성되어 있다.
최근 엘라스틱社는 솔루션 포트폴리오를 Search, Observability 및 Security의 세 가지 영역으로 나누어 확장하고 있다. 엘라스틱 스택을 기반으로 하며 추가 제품은 자체 개발하거나 M&A로 확보해 시장 요구에 부합하는 상품과 서비스를 제공하겠다는 계획이다.
본 아티클은 엘라스틱 스택의 중심축인 엘라스틱서치 검색엔진을 상기 세 가지 관점에서 살펴보고자 한다.
Search
검색 질의에 대한 답변
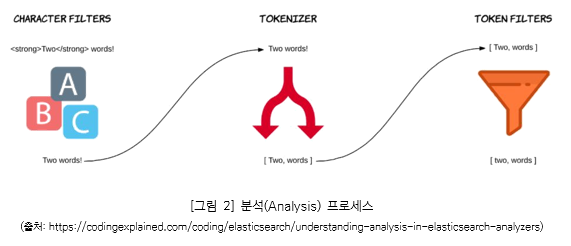
엘라스틱서치에서는 단일 데이터 단위를 도큐먼트(Document)라고 하며 이 도큐먼트를 모아놓은 집합을 인덱스(Index)로 칭한다. 엘라스틱서치는 데이터가 유입될 때 인덱싱(indexing)이라는 프로세스를 진행하여 검색 및 통계를 위한 도큐먼트를 확보한다. 이 과정을 좀 더 살펴보려면 인덱싱 과정에서 검색어를 추출하기 위한 프로세스인 분석(Analysis)을 이해할 필요가 있다. 분석은 캐릭터 필터(Character Filter) – 토크나이저(Tokenizer) – 토큰 필터(Token Filter)로 구성되어 있으며 순차적으로 실행된다.
– 캐릭터 필터(Character Filter)는 불필요한 데이터의 삭제, 변경 등 입력된 원본 데이터를 분석에 필요한 형태로 변환한다.
– 토크나이저(Tokenizer)는 검색의 기초 데이터로 사용하기 위해 필요로 하는 키워드 데이터로 분리한다.
– 토큰 필터(Token Filter)는 토크나이저 작업 시 발생한 불필요한 데이터를 삭제하거나 영문인 경우 모두 소문자로 변경하는 등 꼭 필요한 중요 데이터만 남기고 분석 작업을 종료한다.
대부분의 외산 소프트웨어가 그렇듯 엘라스틱서치 역시 영어권 문자와 숫자의 인덱싱 작업을 위한 기능을 내재하고 있는 반면 한글 등 비영어권 언어에 대한 지원은 다소 취약한 편이다. 다행스럽게도 2018년 노리(Nori)라는 한글 분석기가 제공되어 검색 속도 및 기능이 일부 개선되었으나 보다 세밀하게 지원되어야 할 부분도 여전히 남아있다.
통계 질의에 대한 답변
검색 질의와 달리 통계와 소팅(Sorting, 일정한 조선에 따라 배열) 질의에 대한 답변 데이터는 기본 제공되는 키워드(keyword) 형식의 필드를 통해 인덱싱 한 후 doc_value에 저장된다. doc_value는 엘라스틱서치에서 사용하는 기본 캐시로 효율적인 메모리 관리를 위해 메모리에 적재된 도큐먼트를 인덱싱 하는 대신에 인덱스 데이터와 함께 디스크에 저장하고 그 값을 이용한다. 데이터는 열 지향(Column-oriented) 방식으로 저장하기 때문에 빠른 답변이 가능하다. 따라서 통계와 소팅 질의에는 가능하면 키워드라는 필드를 사용하여야 한다.
참고로 키워드 필드를 사용하지 않고 분석을 거친 필드에 통계와 소팅 질의를 할 수는 있다. 그러나 이를 위해서는 필드데이터(Fielddata) 사용 옵션을 활성화한 후 첫 질의에 대한 응답을 위해 상당량의 메모리를 사용하여 분석된 데이터로부터 값을 가져온 다음 통계와 소팅을 위한 데이터를 필드데이터에 저장한다. 이 필드데이터는 JAVA Heap 메모리에 상주하기 때문에 메모리 부족(Out-of-memory)을 유발할 수 있음을 유의해야 하며 엘라스틱서치가 다수의 버전 업그레이드 후 키워드 필드를 도입한 이유이기도 하다.
Search에 대한 응답에서 한 가지 주목할 만한 사항은 신속성이다. 도큐먼트의 집합인 인덱스가 샤드(Shard)라는 단위로 분리되어 각 노드(Node)에 분산 저장되면서 엘라스틱서치는 분산 시스템의 면모를 가진다. 이로 인해 대량의 질의에도 전체 데이터가 아닌 각 샤드에 분산된 데이터를 기준으로 답변한다. 샤드 데이터를 활용하기 때문에 신속성을 우선시 할 수 있는 것이다. 만약 전체 데이터를 기준으로 응답할 필요가 있는 경우 옵션으로 이를 지원하지만 답변의 신속성이 저하될 수 있음을 감안해야 한다.
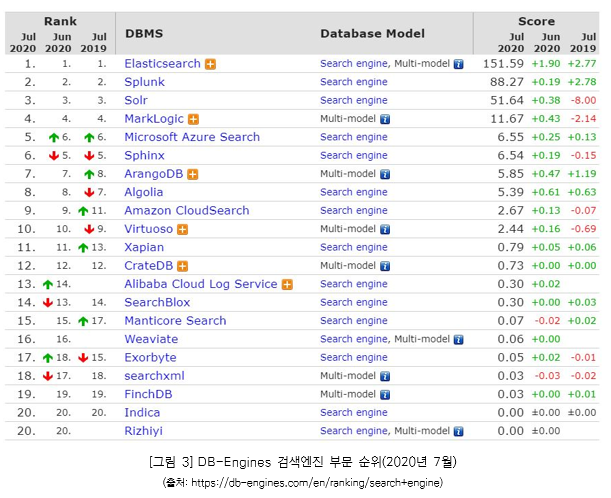
이와 같이 엘라스틱서치는 대용량 데이터 검색을 빠른 속도로 처리하기 위한 기술적 특성을 내재하고 있어 시장에서 많은 주목을 받고 있다. DBMS 관련 인기도 등을 평가하여 매월 순위를 매기는 DB-Engines Ranking에 따르면 2020년 7월 현재 엘라스틱서치는 검색엔진 분야에서 조사 대상 21개 솔루션 중 1위를 차지하고 있다.
Observability
언어가 포함된 검색 데이터를 제외하면 Observability 및 Security와 관련된 대부분의 데이터 여정은 머신(Machine, 컴퓨팅 장치) 데이터로부터 시작된다고 볼 수 있다.
여기서 잠시 머신 데이터의 중요성을 이해할 필요가 있다. 머신 데이터는 정보 데이터이기 때문에 정확성뿐 아니라 최신성도 중요하다. 따라서 생성 시간이 없는 정보 데이터는 효용성과 활용성 측면에서 유의미하지 않을 수 있다. 만약 시계열 데이터를 보유하고 있지 않다면 Observability와 Security 측면에서 엘라스틱서치의 활용 여부를 다시 한번 고려해 봐야 할 것이다.
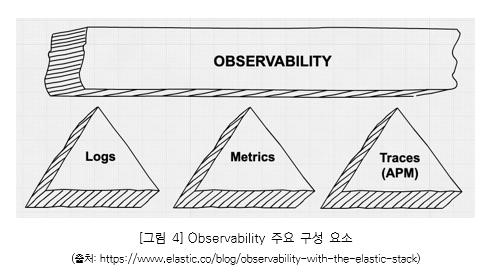
[그림 4]와 같이 Observability는 Logs, Metrics 그리고 APM(Application Performance Management, 애플리케이션 성능 관리)의 세 가지 기능으로 구성되어 있다.
– Logs: 로그(Log) 데이터를 머신에서 이벤트가 발생할 때마다 생성되는 데이터로 이해하여 받아들인다.
– Metric: 머신이 일정 주기로 측정하여 만든 측정 데이터로 이해하여 받아들인다.
– APM: Logs와 Metric을 통해 받아 들인 데이터를 종합·추적하여 운영 중인 애플리케이션의 성능 분석을 용이하게 한다.
엘라스틱서치의 Observability는 머신 데이터를 기반으로 데이터 생명 주기 관점에서 시각화를 통해 그 기능을 수행한다고 볼 수 있다. 엘라스틱서치는 시계열 머신 데이터에 대해 인덱스 라이프사이클 관리(Index Lifecycle Management, ILM)를 제공하여 정책에 따른 인덱스의 생(Hot), 노(Warm), 병(Cold), 사(Delete)를 관리할 수 있게 한다. 로그 수집 시스템을 예로 들면 다음과 같다.
– 오늘 로그는 활발하게 인덱싱 되고 있고 이번 주 로그는 가장 많이 검색된다. → Hot
– 지난 주 로그는 검색되기는 하지만 이번 주 로그만큼 자주 검색되지는 않는다. → Warm
– 지난 달 로그는 자주 검색되지 않을 수 있지만 만약의 경우를 대비하여 유지하는 것이 좋겠다. → Cold
– 지난 달 이전의 로그는 더 이상 필요가 없으니 삭제해도 무방하다. → Delete
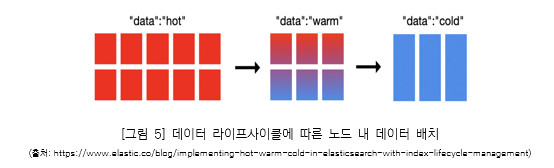
이러한 관리는 앞서 설명한 정보의 최신성을 기반으로 데이터를 달리 배치함으로써 다량의 데이터로 인한 검색 및 통계 처리 시 성능 저하 방지, 스토리지 비용 절감 및 데이터 신뢰도 향상 효과를 가져온다.
축적된 데이터를 기반으로 인사이트와 스토리텔링을 할 수 있게 도와 주는 시각화는 키바나가 담당한다. 키바나는 엘라스틱서치의 데이터 시각화를 위한 사용자 인터페이스(User Interface, UI) 도구로 출발하여 시스템 관리자 기능까지 확대 적용되면서 엘라스틱 스택의 중요한 축이 되고 있다.
키바나를 사용하기 위해서는 먼저 인덱스 패턴 설정이 필요하다. 인덱스 패턴은 사용자가 조사하기 원하는 엘라스틱서치 인덱스를 키바나에 알려주는 역할을 한다. 특정 인덱스를 대상으로 인덱스 패턴을 생성할 수 있으며 데이터를 검색하거나 시각화를 실행할 때 인덱스 패턴을 선택하면 된다.
키바나 애플리케이션은 디스커버(Discover), 비주얼라이즈(Visualize), 대시보드(Dashboard)의 3개 주 메뉴로 구성되어 있다.
디스커버는 원본 도큐먼트를 검색하거나 필터링 할 수 있는 도구이다. 수집한 데이터의 정형화된 모습과 필요 데이터 검색, 필드를 구성하는 데이터의 간단한 통계 수치 등을 확인할 수 있다.
비주얼라이즈는 축적된 데이터를 막대 그래프, 파이 차트, 타일맵, 지도 등 다양한 형식으로 시각화하여 보여준다. 생성한 그래프와 차트는 키바나가 아닌 다른 시스템에서 사용할 수 있도록 임베디드 코드(Embedded code)를 지원한다. 데이터가 변경될 경우 그래프와 차트에 반영되는 세이브드 오브젝트(Saved object) 혹은 변경 사항이 적용되지 않는 스냅샷(Snapshot) 중 하나를 선택해 사용하면 된다.
대시보드는 비주얼라이즈를 통해 시각화한 객체를 모아 하나의 화면에서 확인할 수 있도록 한다. 데이터 생성 시간 및 유스케이스(Use case)에 부합하는 다양한 조건으로 문제점 및 특이사항에 대한 드릴 다운(Drill down)을 할 수 있다. 이는 운영 및 개발에서 APM을 통해 디버깅이나 문제점을 직관적으로 확인할 수 있도록 돕는 중요한 기능이다.
참고로 엘라스틱서치 머신 러닝(Machine Learning)의 이상 징후 탐지에서도 일반적인 조건을 벗어나는 경우 비주얼라이즈와 대시보드를 통해 문제 지점을 찾아서 빠른 조치를 할 수 있다.
디스커버, 비주얼라이즈, 대시보드 외 키바나는 엘라스틱서치의 각 클러스터 및 노드 모니터링도 가능하다. 이 현황 데이터는 주기적으로 각 노드로부터 수집되며 임계치를 설정하여 위험 요소 발생 시 메일 등으로 알림을 받거나 웹훅(Webhook)을 통한 자동 스크립트를 실행해 사람의 개입 없이 신속하게 대응할 수 있다.
Security
엘라스틱서치는 보안 정보와 이벤트 관리(Security Information & Event Management, SIEM) 솔루션을 키바나에 탑재하여 외부의 시스템 공격이나 이상 징후를 선제적으로 방어하고 조치할 수 있도록 한다. 이 부분은 다양한 유스케이스를 기반으로 엘라스틱서치 SIEM에 대한 이해가 필요하기 때문에 다음 기회에 상세히 다뤄보도록 하고 이번에는 엘라스틱서치의 인증 및 권한에 대해 살펴보기로 한다.
엘라스틱서치를 통해 전송되는 데이터를 허가되지 않은 사용자의 접근과 의도치 않은 수정으로부터 보호하기 위해 가장 먼저 구축해야 하는 것이 바로 인증 절차이다. 엘라스틱서치는 외부 업계 표준 ID 관리 시스템과 통합할 수 있다. Active Directory, LDAP 또는 Elasticsearch 네이티브 영역(Realm)으로 사용자 인증이 가능하다.
아울러 사용자에게 할당된 역할에 기반하여 접근을 통제하는 RBAC(Role Based Access Control)와 보안 대상의 속성을 이용하여 접근을 통제하는 ABAC(Attribute Based Access Control)를 통한 권한 관리를 지원한다. 도큐먼트 레벨의 보안을 위해서는 해당 도큐먼트를 식별할 수 있는 쿼리문이 추가로 입력되어야 한다. 따라서 엘라스틱서치 쿼리에 대한 사전 지식이 필요할 수 있다.
ABAC는 속성을 이용하여 RBAC보다 세밀한 권한 관리를 할 수 있다. 사용자 생성·변경 시 템플릿 쿼리(Template query)를 이용하여 설정된 속성과 도큐먼트 매핑 필드(Document mapping field)의 속성 간 쿼리를 통해 도큐먼트 접근을 관리한다. 따라서 속성과 이를 바탕으로 한 권한 정책의 설계가 매우 중요하며 권한 관리를 위한 사용자 인터페이스 개발이 추가로 필요할 수 있다.
시중에는 다양한 ABAC 솔루션이 존재하며 엘라스틱서치는 ABAC 솔루션이 아닌 ABAC를 위한 기본 기능을 제공한다는 점을 염두에 둬야 한다.
엘라스틱서치는 데이터 간 통신 보안을 위해 클러스터 내에서는 TLS(Transport Layer Security, 전송 계층 보안)를, 클러스터 내·외 데이터 통신 시에는 SSL(Secure Sockets Layer, 보안 소켓 계층)을 지원한다. SSL을 위한 자체 사설 인증 기관의 인증서뿐 아니라 공인 인증 기관의 인증서도 사용할 수 있다. 다만 사설 인증서의 경우 외부에서 https를 통한 접속 시 안전하지 않은 사이트라는 메시지가 보이는 점은 감안해야 한다. 이 외 엘라스틱서치는 Space 기능도 제공하는데 사용자 별로 Space 권한을 부여하여 대시보드, 비주얼라이즈 및 다른 저장된 개체 등에 대한 접근 가능 여부를 설정할 수 있다.
도입 시 고려 사항
기업 여건에 맞는 서브스크립션 선택
앞에서 살펴본 바와 같이 엘라스틱서치는 Search, Observability 및 Security를 위한 다양한 소프트웨어를 갖추고 있으며 기본 기능은 무료로 사용할 수 있는 베이직 서브스크립션(Basic Subscription)을 제공한다. 따라서 사용자 입장에서는 기본 기능만으로도 검색 시스템을 쉽게 구축할 수 있을 것으로 생각하기 쉽다. 그러나 기업의 엘라스틱서치 도입 사례를 살펴보면 기본 기능으로는 한계가 있음을 알 수 있다.
글로벌 철강 제조 기업인 A사는 타 사의 검색 솔루션을 사용하다가 엘라스틱서치로 전환하면서 데이터 보안, 대용량 데이터 연계 및 시스템 안정성을 이유로 유료 기술 서비스인 플래티넘 서브스크립션(Platinum Subscription)을 사용하기로 결정했다. 이를 통해 검색 결과의 정확도를 높인 것은 물론 인덱싱 처리 속도도 향상되어 대량 데이터를 안정적으로 관리할 수 있게 되었다.
전문 기술서비스 활용
엘라스틱서치는 자바 가상 머신(Java Virtual Machine, JVM)에서 구동되기 때문에 JVM Heap 메모리 등의 자원 사용률이 높은 통계 집계 질의와 인덱싱은 시스템에 부담을 주어 장애를 발생시킬 수 있다. 엘라스틱서치의 활용도가 높아질수록 현업이 요청하는 유스케이스도 증가하면서 질의 및 인덱스 설계 최적화가 중요해진다. 또한 유스케이스에 따라 데이터 복구 및 정합성 보장에 대한 현업의 요구가 거세질 수도 있다. 따라서 시스템 도입 초기 인덱스 설계에서부터 사용 시 발생하는 각종 요구 사항에 대한 응대 및 문제 해결에 이르기까지 엘라스틱서치의 원활한 사용과 운영관리를 돕는 외부 전문 기술 서비스를 활용하는 것도 고려할 필요가 있다.
에스코어는 국내 최초의 엘라스틱서치 MSP(Managed Service Provider)로서 엘라스틱社가 공인한 엔지니어로 구성된 전문가 조직이 기술 조언, 문제 해결 및 케어팩(Carepack) 서비스를 원스톱으로 제공한다.
업그레이드 시 임의 수정 코드 반영 확인
IT 환경 진화에 발맞추어 엘라스틱서치도 신속한 버전 업그레이드가 이루어지고 있다. 그런데 오픈소스인 엘라스틱서치의 일부 기능을 기업 시스템 관리자가 임의로 수정하고 이를 정식 제품 코드에 반영하지 않을 경우 엘라스틱서치 버전 업그레이드 시 이전에 임의 수정했던 기능을 사용할 수 없게 되어 운영 상 어려움을 겪게 될 수 있다.(엘라스틱社는 사용자의 기능 추가 및 향상에 대한 기여를 장려한다.)
이에 가능하면 제품의 정식 발행 코드를 변경 없이 사용하길 권장하며 불가피한 경우 임의 수정한 부분이 적용하고자 하는 제품의 정식 발행 코드에 반영되었는지 꼭 확인해야 한다.
# References
- https://www.globalonlinetrainings.com/elk-stack-training
- https://codingexplained.com/coding/elasticsearch/understanding-analysis-in-elasticsearch-analyzers
- https://www.elastic.co/blog/observability-with-the-elastic-stack
- https://www.elastic.co/blog/understanding-query-then-fetch-vs-dfs-query-then-fetch
- https://logz.io/blog/runkeeper-elk-stack
- https://towardsdatascience.com/an-overview-on-elasticsearch-and-its-usage-e26df1d1d24a
- https://www.elastic.co/blog/implementing-hot-warm-cold-in-elasticsearch-with-index-lifecycle-management
- https://www.elastic.co/guide/en/kibana/current/tutorial-define-index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/authorization.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/glossary.html
- https://www.elastic.co/guide/en/elasticsearch/reference/master/realms.html
- https://www.elastic.co/guide/en/kibana/current/development-security-rbac.htm• • l
- https://en.wikipedia.org/wiki/Webhovok
- https://db-engines.com/en/ranking/search+engine
- https://trends.google.com/trends/explore?date=all&q=elasticsearch
- https://www.elastic.co/kr/customers/posco
- https://searchitchannel.techtarget.com/definition/managed-service-provider
- https://support.s-core.co.kr/hc/ko/categories/360000137273
김수만 프로
에스코어㈜ 소프트웨어사업부 컨버전스SW그룹
에스코어 소프트웨어사업부에서 Elasticsearch 기술 서비스를 담당하고 있습니다.



Register for Download Contents
- 이메일 주소를 제출해 주시면 콘텐츠를 다운로드 받을 수 있으며, 자동으로 뉴스레터 신청 서비스에 가입됩니다.
개인정보 수닙 및 활용에 동의하지 않으실 경우 콘텐츠 다운로드 서비스가 제한될 수 있습니다.
파일 다운로드가 되지 않을 경우 s-core@samsung.com으로 문의 주십시오.